캐시 전략
기본적으로 웹서비스 경우 데이터베이스 통해 수집, 저장, 관리, 검색 역할을 하고 있습니다. 하지만 많은 트래픽이 발생이 하면 캐싱을 하게 되는데 기본적으로 데이터베이스 (디스크) 보다 메모리 (RAM) 같은 빠른 임시 저장소에 저장 해서 관리 하게 됩니다. 이는 어플리케이션 응답 속도를 획기적으로 높이고, 데이터베이스 부하를 줄이는데 획기적인 방법 입니다.
하지만 캐싱을 사용하는데 있어서 주의할 점이 몇 가지 있습니다. 캐싱을 잘못 사용하면 캐시를 사용했는데도 데이터베이스에 많은 부하가 발생 할 수 있기 때문입니다.
다음은 몇 가지 대표적인 주의 할 점과 해결 방안에 대해 소개 하고자 합니다.
Cache Penetration (캐시 관통)
Cache Penetration 는 일반적으로 조회 하고자 하는 데이터가 데이터베이스에도 없고 캐시에도 없는 데이터를 요청이 계속 들어와서 , 매번 원본(데이터베이스) 까지 뚫고 들어가는 현상 을 말합니다.

처음 특정 데이터 조회 요청 들어오면 우선 캐시에 조회를 할 것이고 찾고자 하는 데이터가 존재하지 않으면 Cache miss 가 발생 합니다. 그 다음 원본 (데이터 베이스) 까지 조회 했는데도 찾고자 하는 데이터가 존재 하지 않으면 null 데이터를 응답 받게 됩니다. 이때 null 로 저장을 했으니 캐시에는 저장 않게 됩니다.
두번째 요청에도 첫번째 요청과 동일하게 찾고자 하는 데이터가 동일 하면 우선 캐시에 데이터가 존재하는지 조회 하지만 동일하게 Cache miss 가 발생 할 것이고 데이터베이스에도 조회를 했지만 당연히 조회 되지 않아 null 로 반환 하게 됩니다.
이렇게 Cache Penetration 는 보통 캐시 및 데이터베이스에 모두 찾고자 하는 데이터가 존재하지 않을 경우 캐시 저장소, 원본 저장소 (데이터베이스) 조회를 했지만 결국은 null 로 반환되고, 결국은 원본 저장소까지 부하를 전파 되면서 케시에 이점을 활용 하지 못 하는 현상이 발생 하게 됩니다.
다음은 이러한 문제를 해결하기 위해 Null Object Pattern Bloom Filter 에 대해서 소개 하고자 합니다.
Null Object Pattern
앞써 설명한 대로 null 로 응답 받아서 캐시에 저장 하지 않게 되면서 이후 동일한 요청이 들어와도 캐시 저장소 → 원본 저장소 까지 관통 되면서 조회 미스가 계속 발생 하게 됩니다.
Null Object Pattern 는 null 를 그대로 전파하지 않고, ‘없음’ 을 의미하는 객체 (Null Object) 를 만들어 일반 객체처럼 동일하게 취급 하는 패턴 입니다.
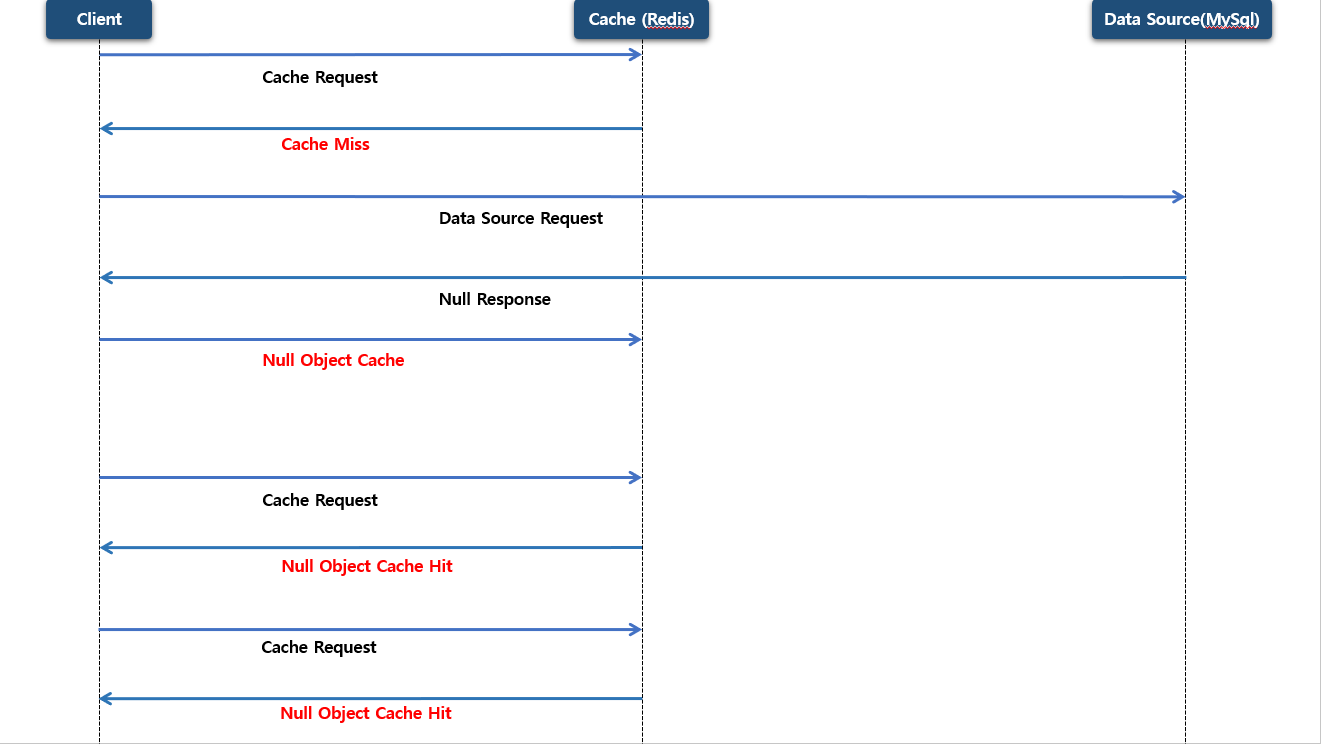
요청 하고자 하는 데이터를 먼저 캐시 저장소에 조회를 하고 Cache miss 가 발생 하게 됩니다. 이 후 원본 저장소에 조회를 하지만 찾고자 하는 데이터가 없어서 null 로 반환하게 됩니다. 그 다음 객체 (Null Object) 를 만들어서 캐시 저장소에 저장을 하게 됩니다.
이후 클라이언트가 동일한 요청 (동일 키로 다시 요청) 을 하게 된다면 캐시 저장소에 조회 해서 이전에 만들었던 객체 (Null Object) 를 반환하게 됩니다.(Cache hit) 이렇게해서 원본 저장소 까지 관통하지 않게 되면서 부하를 최소화 할 수 있게 됩니다. 즉 “없음도 캐시에 저장한다” 를 null 대신 의미 있는 객체 (Null Object) 로 저장하는 방식 입니다.
Bloom Filter
Bloom Filter 는 특정 데이터가 존재하는지 를 빠르게 판별하는 확률적 자료구조 (Probabilistic Data Structure) 입니다.
특징은 찾고자 하는 데이터가 존재하지 않으면 확실히 존재하지 않고 만약 확률적으로 존재한다고 판단하는 경우 있을 수도 있고 없을 수도 있습니다. 즉 False Positive (잘못된 긍정) 로 표현 할 수 있겠습니다.
이해하기 쉽게 그림으로 설명 하도록 하겠습니다.
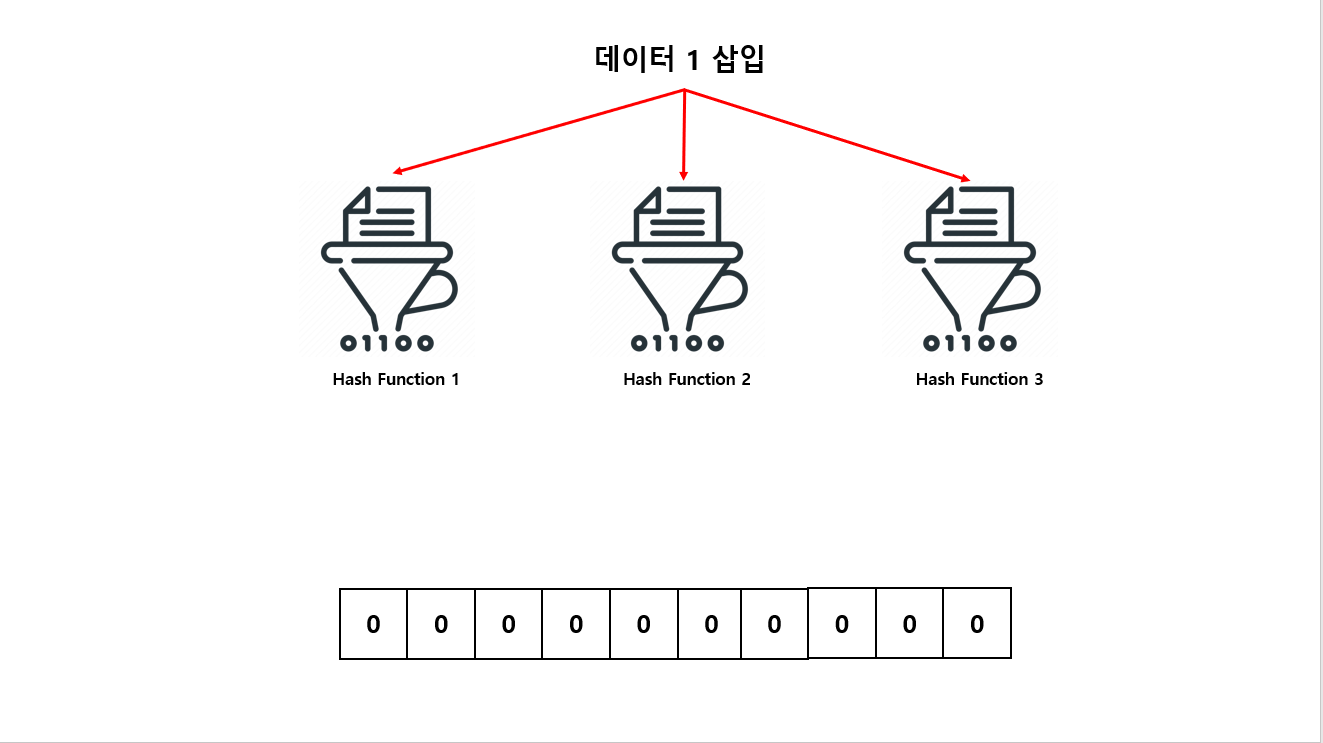
다음과 같이 10개 비트 배열로 구성되어 있는 Bloom Filter 가 있다고 가정 하겠습니다. 그리고 3개의 해시 함수가 존재하는데 각각의 독립적인 해시 함수는 0~9까지 반환 한다고 하겠습니다.
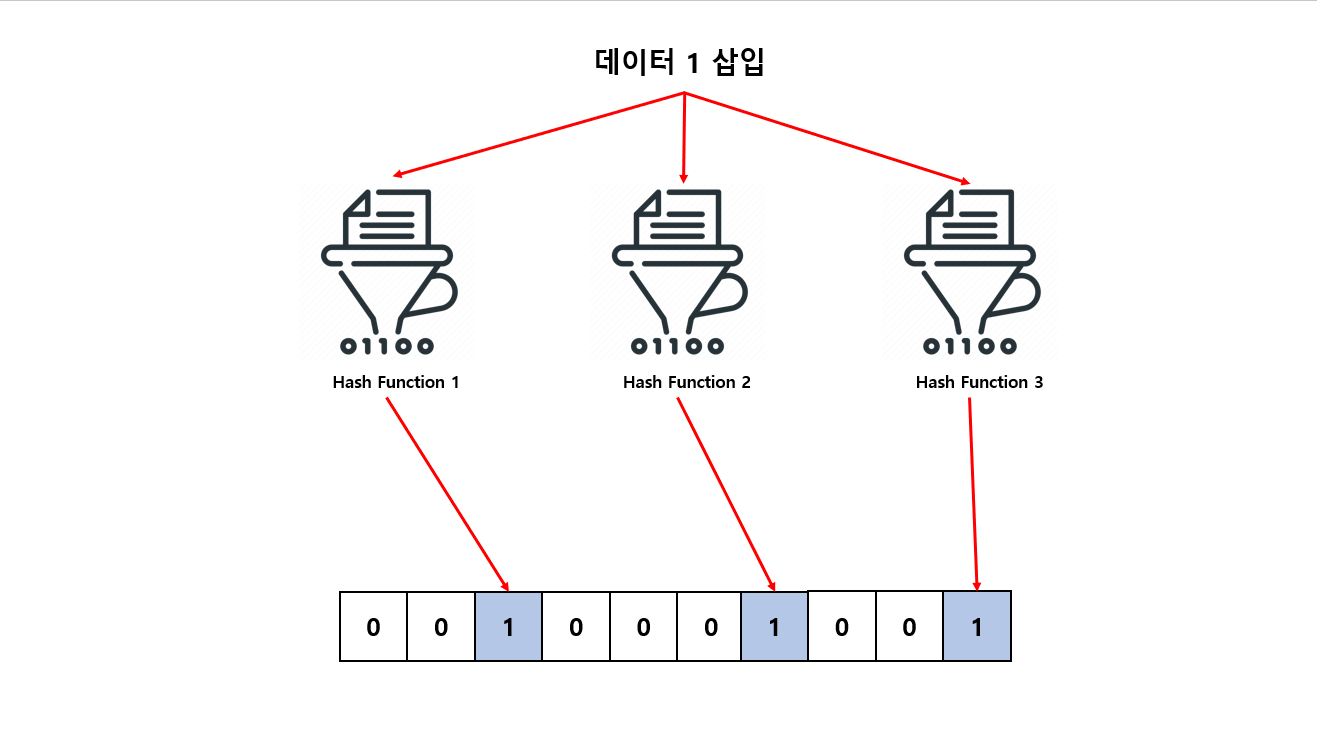
여기서 데이터 1를 입력 하게 된다면
- 1번 해시 함수 → 2
- 2번 해시 함수 → 6
- 3번 해시 함수 → 9
값으로 반환 하게 됩니다.
각각의 반환되는 값은 Bloom Filter 10개 비트 배열 인덱스가 됩니다. 반환 되는 값 인덱스에 Bloom Filter 비트에 0에서 1로 저장 하게 됩니다.
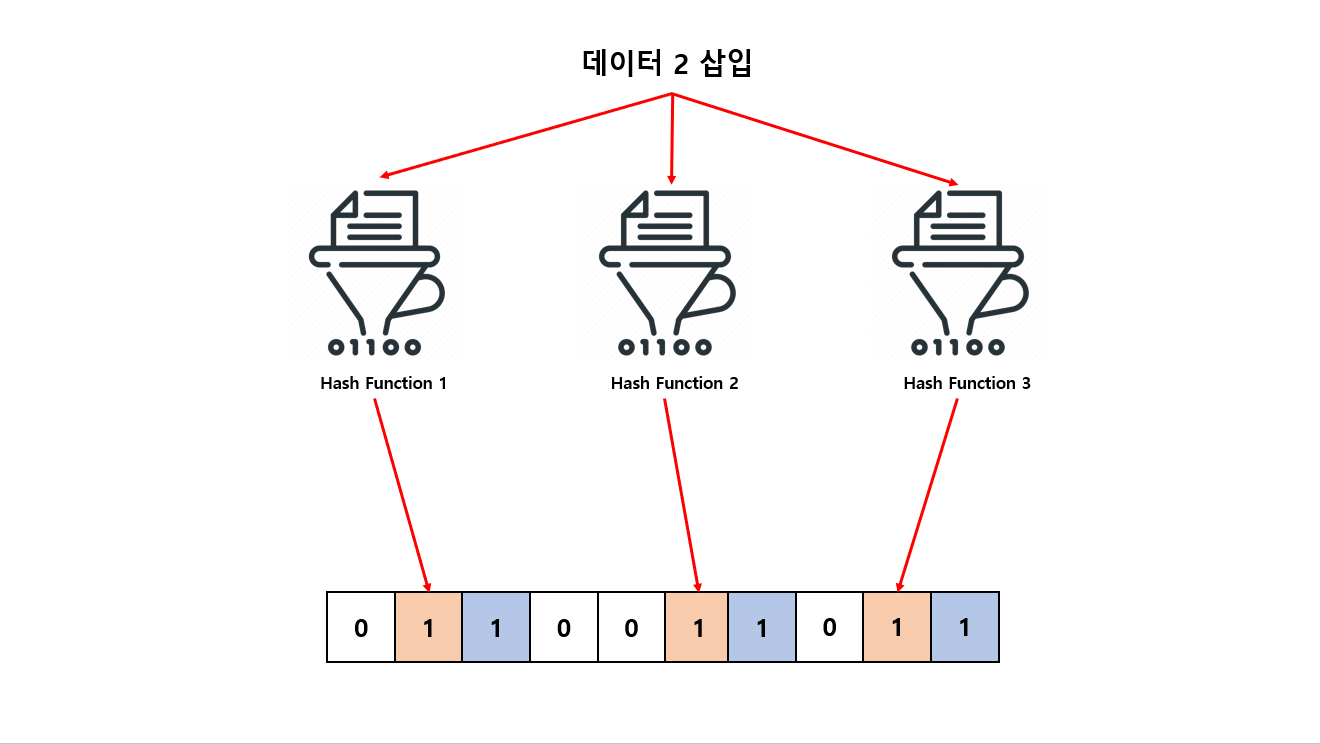
그 다음은 데이터 2 를 입력 하도록 하겠습니다.
- 1번 해시 함수 → 1
- 2번 해시 함수 → 5
- 3번 해시 함수 → 8
값으로 반환 되고 마찬가지로 각각의 반환 되는 값을 Bloom Filter 10개 비트 배열 인덱스에 1로 저장을 합니다.
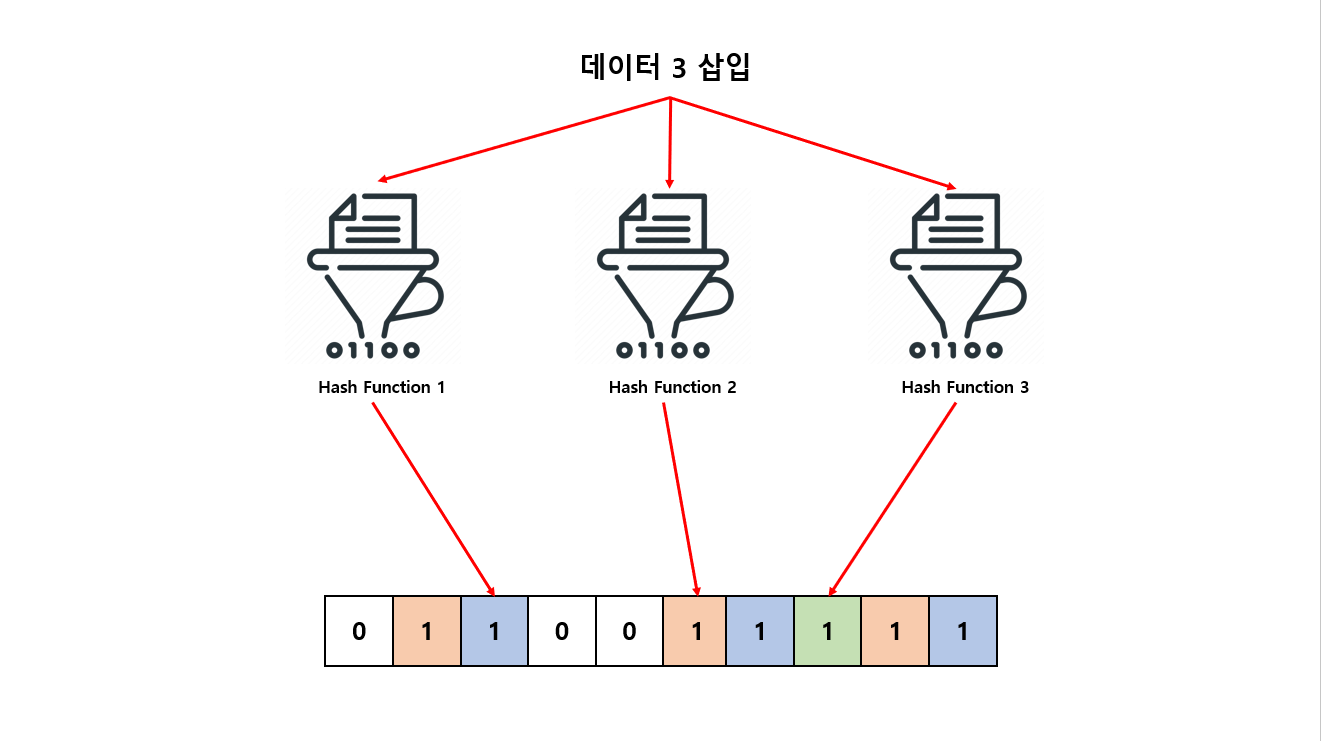
그 다음은 데이터 3 를 입력 하도록 하겠습니다.
- 1번 해시 함수 → 2
- 2번 해시 함수 → 5
- 3번 해시 함수 → 7
값으로 반환 되지만 Bloom Filter 10개 비트 배열 인덱스에 1로 저장 되어 있는 확인을 하는데 이미 인덱스 2, 5 는 1로 저장 되어 있지만 인덱스 7은 저장 되어 있지 않는 상태 입니다.
하나라도 입력 되지 않으면 입력한 데이터 3은 한번도 입력되지 않다고 판단하게 됩니다.
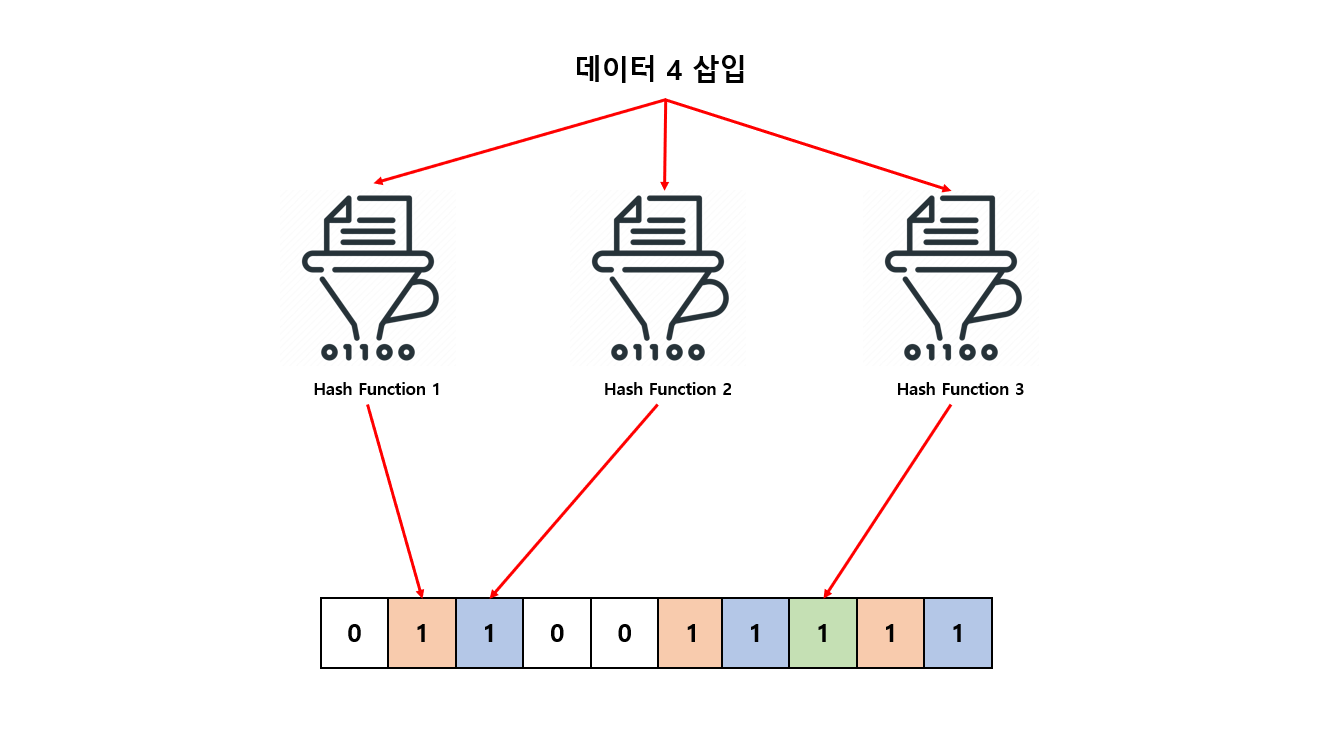
그 다음은 데이터 4 를 입력 하도록 하겠습니다.
- 1번 해시 함수 → 1
- 2번 해시 함수 → 2
- 3번 해시 함수 → 7
각 해시 함수 통해 반환 된 값 1, 2, 7 모두 Bloom Filter 비트 배열에 이미 저장 되어 있습니다. 분명 데이터 4는 입력 된 적이 없었지만 이미 저장되어 있다고 판단 해버립니다. (해시 충돌)
이렇게 해시 충돌 로 인해서 실제로는 입력한 데이터가 아니더라도 있다고 판단 해버리는 상황이 발생 하게 됩니다. 즉 False Positive (잘못된 긍정) 이라고 표현 할 수 있습니다. 이러한 원리로 Bloom Filter 는 확률적 자료구조로 말 할 수 있겠습니다.
이러한 특성 때문에 만약 데이터 4 입력한 Bloom Filter 비트 배열에 저장 된 데이터를 삭제 하고자 할 때 입력한 데이터가 실제로 4 로 인해 저장 된 데이터인지 아니면 다른 값으로 저장 된 데이터 인지 판단 할 수 없어 한번 입력한 데이터는 삭제 할 수 없게 됩니다.
적절한 비트 배열 크기(m) 와 해시 함수 개수(k) 공식
Bloom Filter에서 비트 배열 크기(m) 와 해시 함수 개수(k) 는 보통 내가 얼마나 많은 원소를 넣을 건지(n)와 얼마나 틀려도 되는지(허용 False Positive 확률 p)두 가지를 먼저 정한 뒤 공식으로 계산해서 잡습니다.
n = 예상 삽입 원소 개수
p = 목표 False Positive 확률 (예: 1% = 0.01)
m = 비트 배열 크기
k = 해시 함수 개수
비트 수 (m)
$$
\left( \sum_{k=1}^n a_k b_k \right)^2 \leq \left( \sum_{k=1}^n a_k^2 \right) \left( \sum_{k=1}^n b_k^2 \right)
$$
$\\sqrt{\\$4}
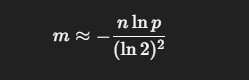
해시 함수 개수 (k)
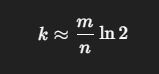
예시로 존재 가능한 데이터가 1천만 개 (n: 10,000,000) 이고 오차율을 0.01로 하고 싶을때
필요한 비트 수 (m):
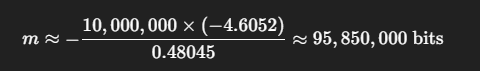
비트를 바이트로 바꾸면:
- 95,850,000 bits / 8 ≈ 11,981,250 bytes = 11.4MB
필요한 해시 함수 개수 (k):
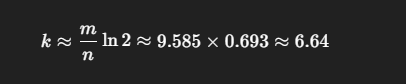
대략 1천만 개 데이터를 0.01 오차율로 Bloom Filter 관리 하고 싶으면 대략 12MB 이면 가능 하다는 계산이 떨어 집니다.
Cache Stampede (캐시 쇄도)
Cache Stampede 는 조회 하고자 하는 캐시 데이터가 마침 캐시 만료로 인해서 Cache miss 가 발생 하는 순간 동시 다발 요청이 한꺼번에 발생해서 여러 번 Cache miss 가 발생 되고 한꺼번에 원본 저장소에 몰리는 현상을 말 합니다. 캐시 만료 뿐만 아니라 아직 캐시 데이터에 저장 되지 않는 상태에서 동시 다발 요청이 들어올 때도 발생 하게 됩니다.

여러 개 요청 (모두 찾고자 하는 데이터가 각각 다를 경우)으로 인해 캐시 데이터로 찾고자 하는 데이터를 질의 하게 되지만 모두 Cache miss 가 발생 한다고 가정 하겠습니다. 그럼 모든 요청이 한꺼번에 원본 데이터까지 질의 하게 되고 부하로 이어져 캐시의 장점이 상실 되는 현상이 발생 하게 됩니다.
이러한 문제를 해결하기 위해
- Jitter
- Probabilistic Early Recomputation (PER)
- Request Collapsing
- Rate Limiter
- Write-Through
방법이 있습니다.
Jitter
**Jitter**는 캐시에 저장할 때 만료 시간(TTL) 을 모든 키에 동일하게 주지 않고 무작위한 랜덤 값을 섞어서 만료 시점을 설정해 분산 시키는 기법입니다.
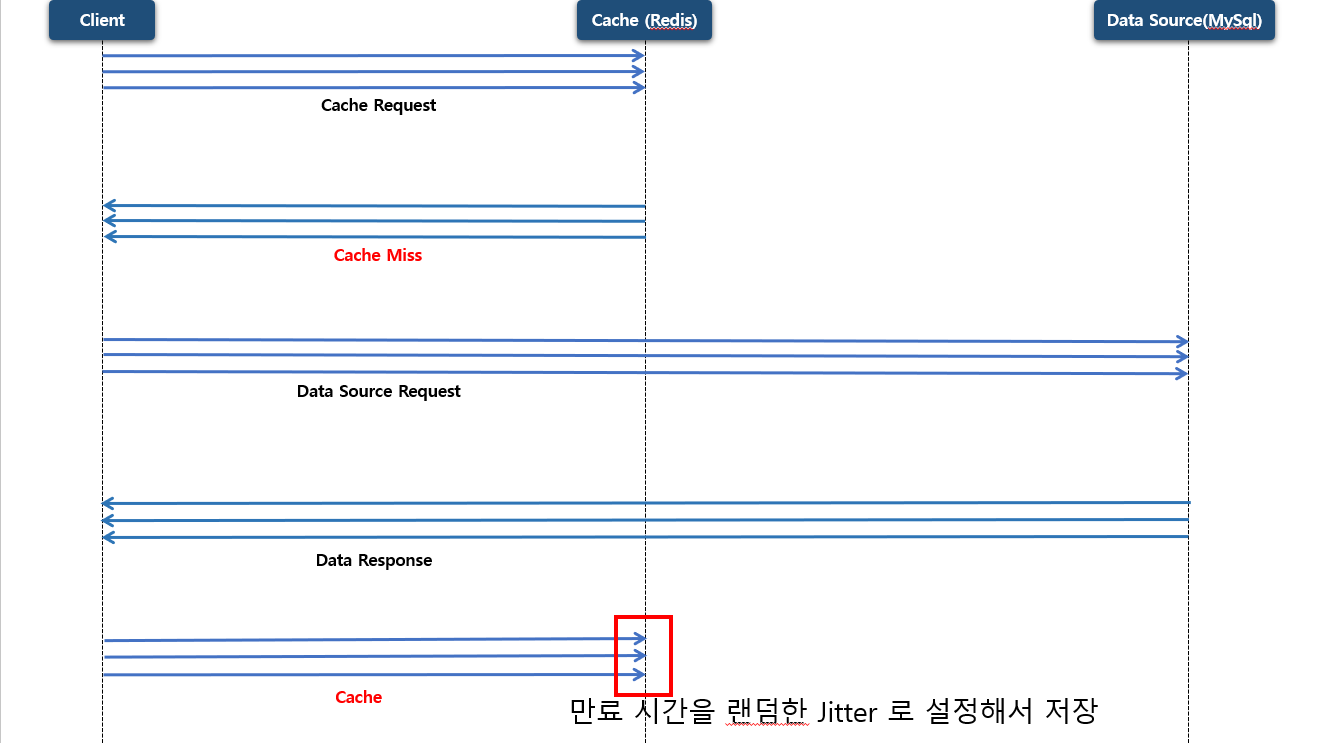
처음에 여러 개 요청 (모두 찾고자 하는 데이터가 각각 다를 경우) 으로 캐시 저장소에 질의를 하였지만 존재하는 데이터가 없고 (Cache miss) 원본 데이터에 질의를 한 다음에 캐시에 데이터를 저장 할 때 만료 시간을 랜덤한 Jitter 로 설정해서 저장 합니다.
이렇게 하면 특정 시점에 캐시가 동시에 비는 현상이 줄고, 원본 저장소로 몰리는 부하 스파이크가 완화됩니다.
Probabilistic Early Recomputation (PER)
PER은 캐시 키가 완전히 만료되기 전에 각 요청이 확률적으로 빠른 시점에 미리 갱신해서 캐시를 조기 재계산(early recompute) 하는 기법입니다.
즉 만료 시간이 다가올 수록 확률이 증가하게 되고, 캐시 갱신이 오래 걸릴 수록 확률이 증가 하게 됩니다.
.png)
1, 2, 3번 요청이 동시에 동일한 키로 캐시 저장소에 요청 한다고 가정 해보겠습니다. 캐시에 요청하고자 하는 데이터가 존재해서 Cache Hit 가 발생 했다고 가정 하고 이때 3개의 요청 중 하나가 확률로 인해서 캐시 갱신에 책임이 생길 수 있습니다.
이러한 확률은 앞서 설명한 대로 만료 시간이 다가올 수록 , 캐시 갱신에 오래 걸릴 수록 확률이 증가 하게 됩니다.
.png)
여기서 1번 2번 요청은 즉시 응답하지만 3번 요청은 캐시 갱신에 책임을 얻어서 캐시 갱신을 하기 위해 원본 데이터에 질의를 하게 되고 다시 캐시 저장소에 저장 해서 캐시 만료 시간을 초기화 하게 됩니다. 이후에 해당 요청이 들어와도 이미 새롭게 캐시를 갱신 하기 때문에 만료 시간 때문에 여러 개 요청이 원본 저장소에 질의 하는 사태는 없어질 것 입니다.
즉 캐시가 만료되기 전에 조기에 캐시 만료 시간을 초기화 하므로써 Cache Stampede 현상을 방지 할 수 있습니다.
PER 알고리즘
1 | XFetch(key, ttl, β=1) |
PER 알고리즘에 대해서 알아보도록 하겠습니다.
파라미터 부터 설명하자면
key : 캐시 키 값
ttl : 만료 시간
β(벨타) : 갱신 시점을 앞당기기 위한 가중치 값 (보통은 1)
이렇게 요청이 들어오고 CacheRead 함수를 통해 요청 하고자 하는 key 값을 이용해서
value : 캐시 데이터
Δ 델타 (Delta) : 재 계산에 소요된 시간
expiry: 캐시 만료 시점
이렇게 데이터를 얻을 수 있습니다.
if 문을 확인 해보면value(캐시 데이터) 값 없거나
now(현재 시간) 에다가 β(벨타) * Δ 델타 (Delta) * log(rand()) 값을 뺀 값에
expiry 만료 시간 보다 같거나 크면 캐시 갱신을 하게 됩니다.
여기서 재계산이 오래 걸리수록 확률이 증가 한다고 했는데 Δ 델타 (Delta) 이 증가 할 수록 확률은 증가 하게 됩니다.
그리고 만료 시간이 증가 할 수록 확률이 증가 한다고 했는데 now(현재 시간) 데이터는 시간이 흐르면 값이 증가 되니깐 그만큼 확률 값도 증가 하게 됩니다.
(now - Δ * β * log(rand())) >= expiry
해당 비교 조건을 임의 값을 매칭 시켜 예시를 만들어 보자면
20 - 2 * 1 * (-2.1) ≥ 25
24.2 ≥ 25
이므로 조건에 부합 되니 캐시 갱신을 안하게 됩니다.
만약 β(벨타) 가중치 값을 2 로 증가 시키면
20 - 2 * 2 * (-2.1) ≥ 25
28.4 ≥ 25
만료 시간 25 보다 더 크니깐 갱신 하게 됩니다.
조건문 안에 들어오면
start <- now : 현재 시간을 저장 합니다.
value <- RecomputeValue() : 원본 저장소에 데이터를 질의 합니다.Δ 델타 (Delta) <- now - start : 재 계산 소요 시간을 계산 합니다.
CacheWrite(key, (value, Δ), ttl) : 캐시에 데이터 값 갱신 하게 됩니다. (만료 시간 초기화 및 델타 값 갱신)
Probabilistic Early Recomputation(PER) 는 캐시 만료 직전에 확률적으로 일부 요청을 갱신을 수행하게 만들어서 만료 시점에 발생하는 Cache miss 폭발 (Cache Stampede) 을 완화하는 기법 입니다.
특히 캐시 값 생성 비용 (Δ 델타) 을 함께 저장하고 만료에 가까워질수록 갱신 확률이 커지도록 설계 하도록 되어 있는데 이는 락 의존도를 낮추면서도 높은 트래픽의 안정적인 효과를 얻을 수 있습니다.
Request Collapsing
**Request Collapsing**은 같은 시점에 들어온 중복된 요청들을 하나로 합쳐서 호출을 1번(또는 소수) 만 하게 만드는 기법입니다.
만약 같은 키에 100 개 요청이 동시에 조회를 하게 된다면 원본 데이터에 100개 요청을 하지 않고 단 1개의 요청으로 합쳐서 요청하는 기법 입니다.
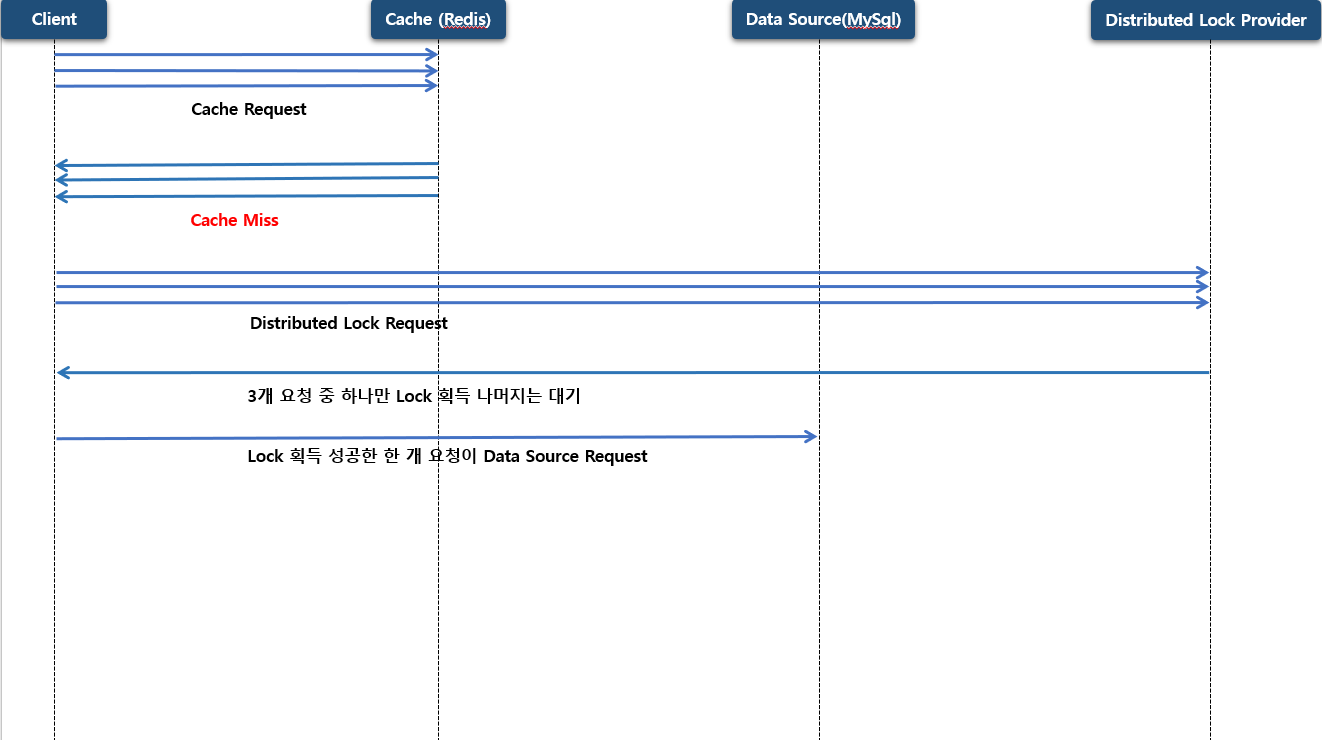
만약 동시에 3개의 중복된 요청이 들어 오고 Cache miss 가 발생 한다고 하면 원본 저장소 까지 조회를 하게 됩니다. Request Collapsing 기법은 하나의 요청으로 합쳐서 원본 저장소에 요청 하게 됩니다.
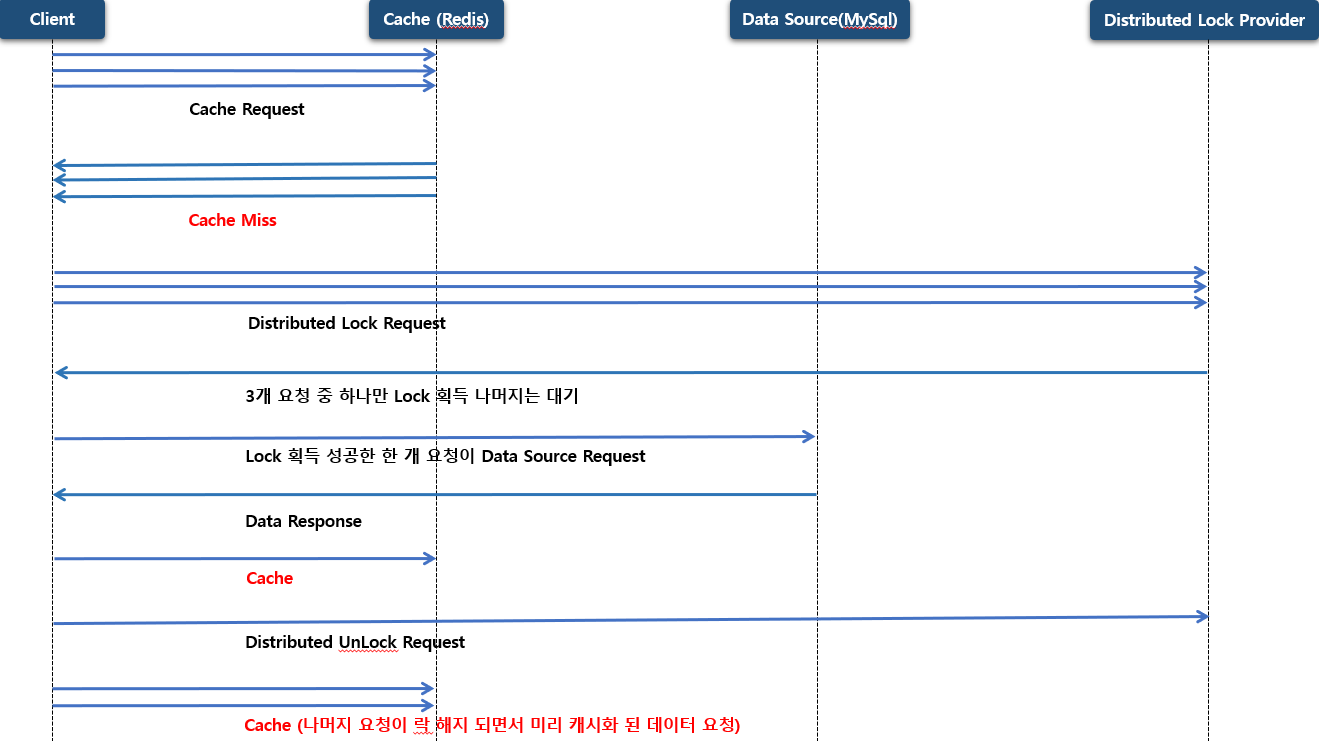
동일하게 동시에 3개의 중복된 요청이 들어 오고 Cache miss 가 발생 한다고 하면 그 다음 원본 저장소에 바로 요청 하지 않고 Distributed Lock Provider 분산락 요청을 합니다. 이때 분산락 요청을 단일 요청만 분산락에 점유를 하게 되고 나머지 요청들은 점유하지 못한 채 대기 상태로 빠져버립니다.
분산락에 점유한 요청은 캐시에 갱신 할 책임을 위임 받게 되고 원본 저장소에 요청을 해서 데이터를 조회 하고 캐시 저장소에 데이터를 갱신 하게 됩니다. 그런 후 분산락을 해제 하게 되고 나머지 요청들은 분산락이 해제 되면서 바로 이전에 저장 된 캐시 저장소에 질의를 해서 조회를 하게 됩니다.
Rate Limit
**Rate Limit**은 특정 주체(사용자 or 토큰 or IP or 키 or 엔드포인트)가 일정 시간 동안 보낼 수 있는 요청 수를 제한하는 기법입니다.
예를 들어서 IP 당 초당 100 요청 제한이 있을 수 있겠습니다. 정해진 제한이 넘으면429(Too Many Requests) 발생 시켜서 일부 요청들은 실패 하겠지만, 적어도 시스템 장애까지는 이어지지 않게 됩니다.
앞써 설명한 Request Collapsing PER Jitter 방식은 ****Cache Stampede 가 발생 할 때 아직 캐시가 존재하지 않거나 요청 하고자 하는 캐시 키가 여러개 일 경우와 같은 모든 상황에 대응 하지 못 할 수가 있습니다. 특히 원본 저장소 에 트래픽이 감당하지 못 할 정도로 요청이 온다고 하면 시스템 장애까지 이어 지는데 이것을 원천적으로 Rate Limit 기능을 이용해서 트래픽을 차단 하는 방법도 좋은 방향 중 하나 일 것 입니다.
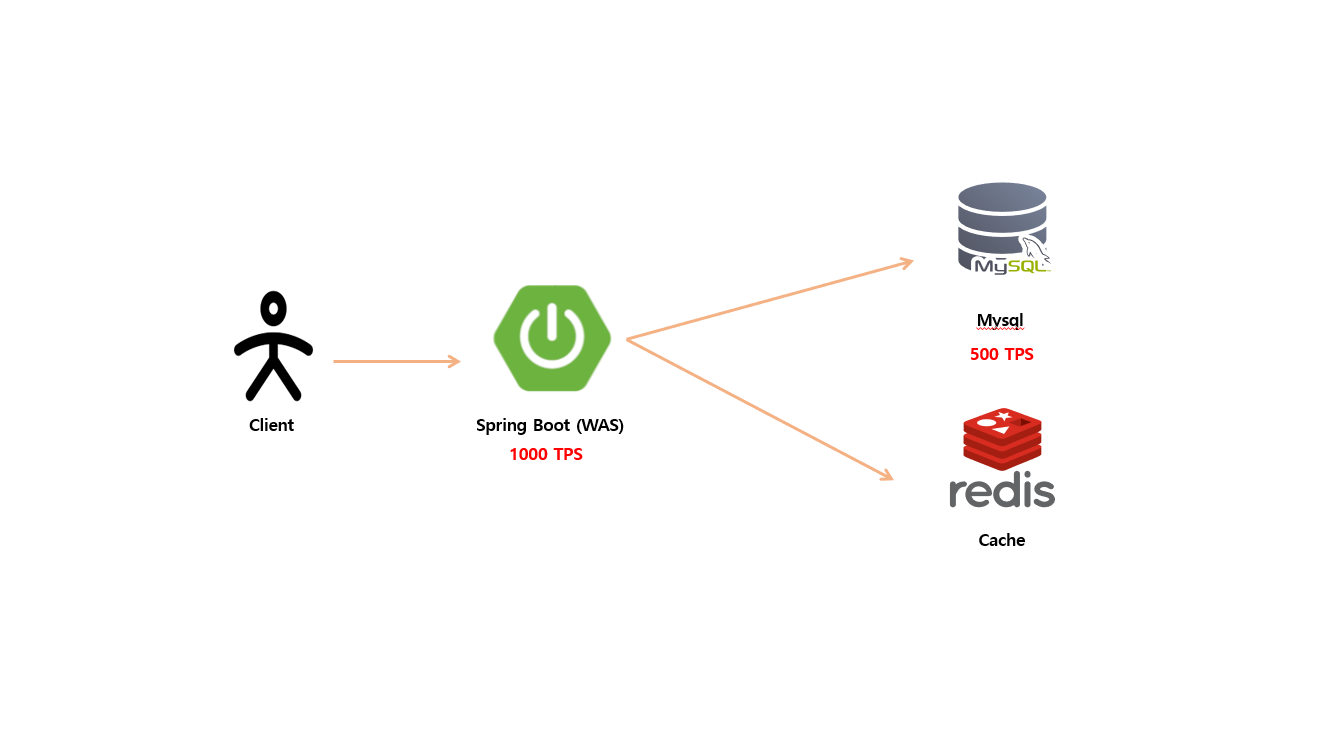
WAS 서버가 1000 TPS 까지 감당 가능 하고 원본 저장소 가 500 TPS 까지 감당 가능 한다고 가정 시 요청 트래픽이 대량으로 올 경우 WAS 서버는 감당 가능 하겠지만 각 요청 하는 캐시 키가 전부 다르고 대부분 요청이 Cache miss 가 발생 한다면 원본 저장소 까지 전파 하게 될 것이고 500 TPS 까지 감당 하지 못 하니 결국은 시스템 장애까지 이어 질 수 있습니다.
이 때 Rate Limit 를 이용해서 요청 수를 제한해 시스템 장애까지 이어지는 것을 방지 할 수 있습니다.
Write Through
Write-Through는 데이터를 쓰기 (write) 할 때 애플리케이션이 캐시와 원본 저장소 (DB) 를 동시에 갱신하도록 만드는 캐시 전략입니다.
지금까지 설명한 캐시 전략들은 Look-Aside 패턴 이었습니다. 즉 조회 시점에 Cache miss 가 발생하면 Cache 를 갱신 하는 방법 이었고 Write-Through 전략은 생성, 수정, 삭제를 할 때 Cache 를 갱신 하는 전략 입니다.
특히 Write-Through 경우는 쓰기 및 변경 작업이 일어나서 바로 읽기 작업이 많이 발생 하는 경우 Write-Through 전략은 적합할 수 있겠습니다. 예를 들어서 자유 게시판 목록 글을 캐시 할 경우가 있겠습니다.
지금까지 알아본 전략 경우 Look-Aside 패턴 이었기 때문에 등록 및 변경 작업이 일어날 경우 그때 마다 캐시 만료를 하면 캐시 히트률 은 떨어지게 됩니다.
Write-Through 전략을 사용 할 경우 주의 할 점이 있는데요. 만약에 특정 데이터가 변경이 일어날 경우 캐시를 업데이트 하고 그 다음 원본 저장소에 업데이트를 하는 과정에 실패가 일어나면 캐시 저장소 하고 원본 저장소와 데이터 일관성이 무너지게 됩니다.
보통 실무에서는 먼저 원본 저장소에 업데이트를 한 다음 성공 한다면 캐시 저장소를 갱신 하거나 비동기 (Write-Behind)로 처리 하게 됩니다.
자유 게시판 같은 목록 데이터는 전체 데이터를 캐시 저장소에 저장 할 수 없으니 보통 첫 페이지 즉 사용자가 많이 조회 하는 페이지만 캐시화 하게 됩니다. Redis 를 사용 하면 Sorted Set 자료구조를 많이 이용 하게 됩니다.
Sorted Set 이용해서 최대 상위 (최신순) 3건만 저장 하도록 구성 할 계획 입니다.
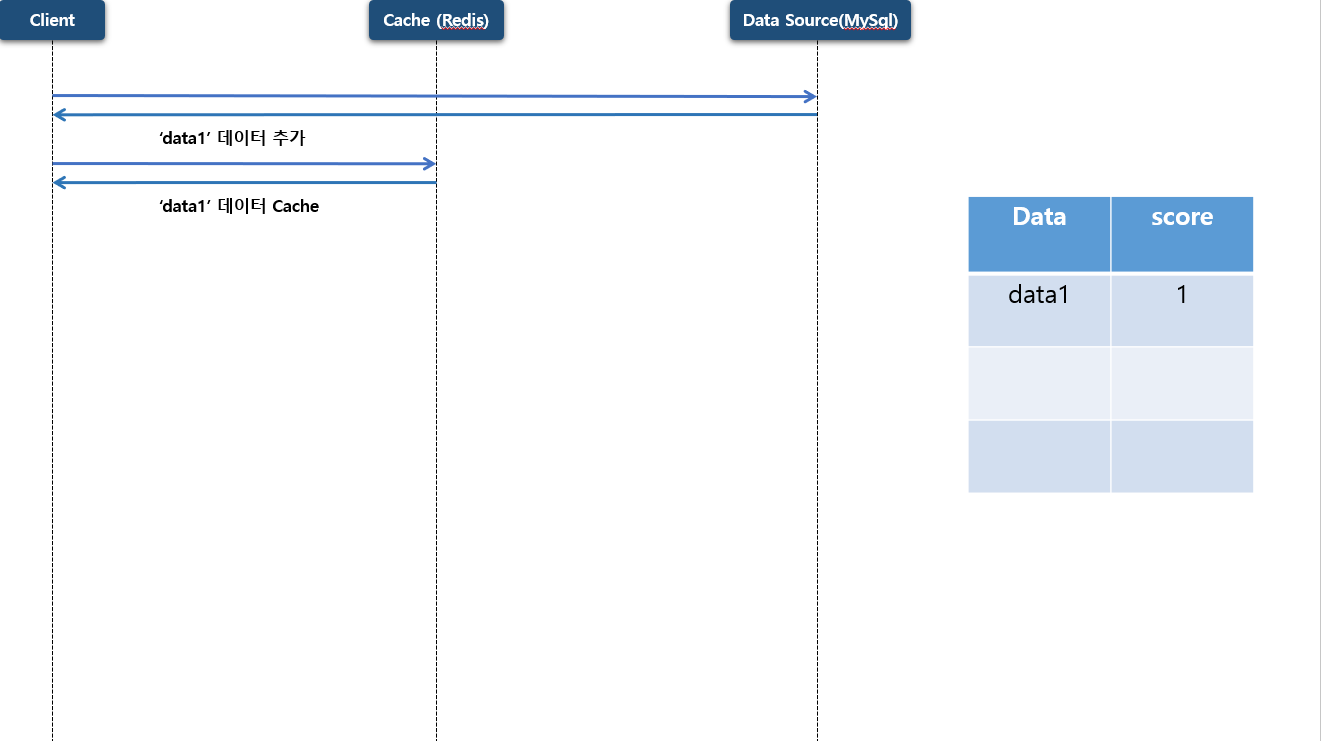
첫번째 데이터가 저장 하게 되면 우선 원본 저장소 에 데이터가 저장을 하게 되고 캐시 저장소 에도 저장을 하게 됩니다. 이때 data 는 list:1 로 저장 되고 score 는 1 로 저장 됩니다.
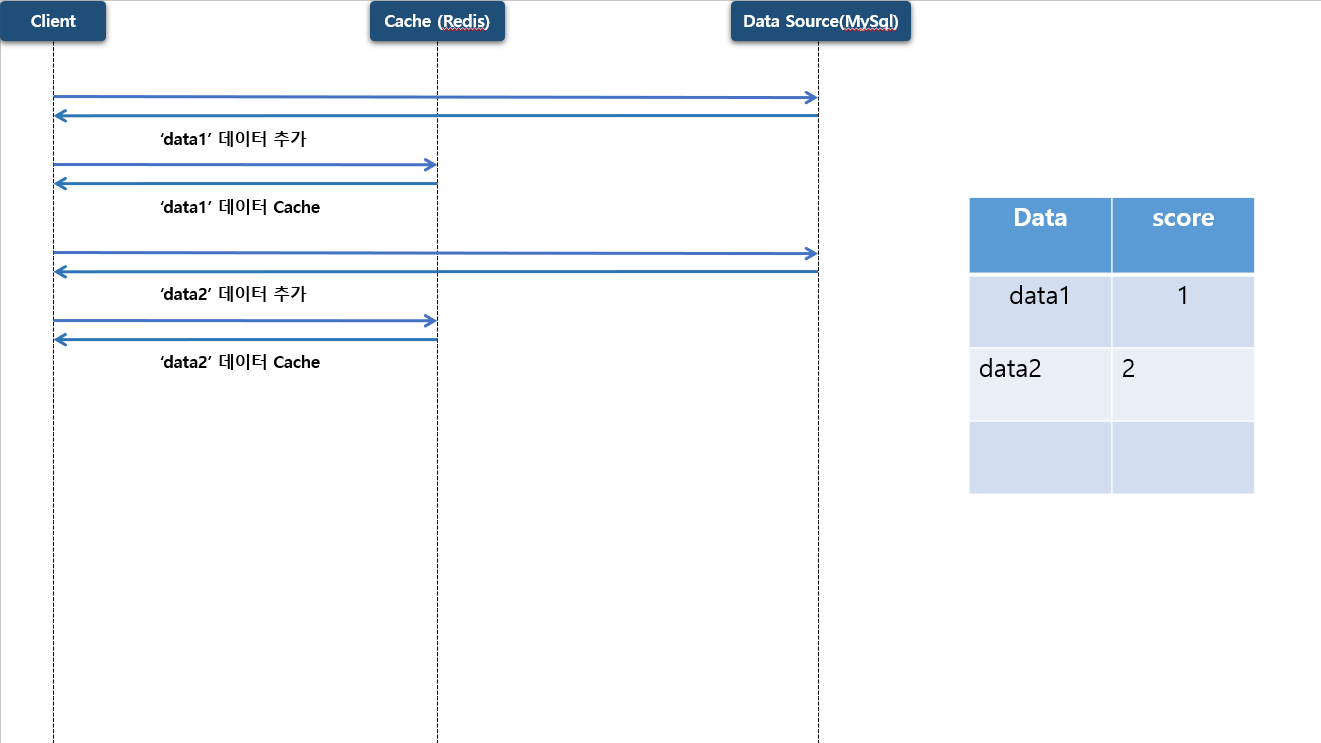
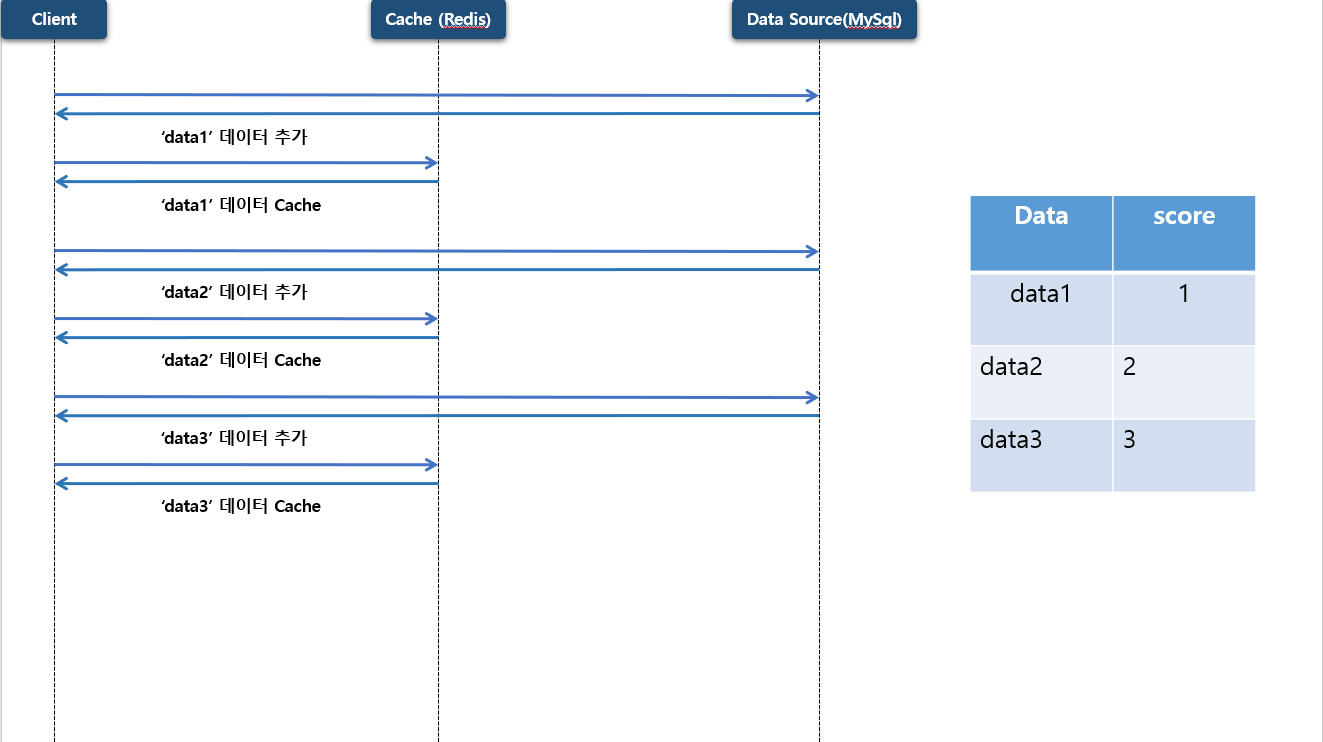
두번째, 세번째 데이터도 동일하게 저장 하게 됩니다.

이 후 네번째 데이터가 저장 하게 된다면 앞써 말한대로 최대 3건만 저장 하도록 되어 있으니 첫번째 저장된 데이터는 삭제 되고 네번째 데이터가 저장 하게 됩니다.
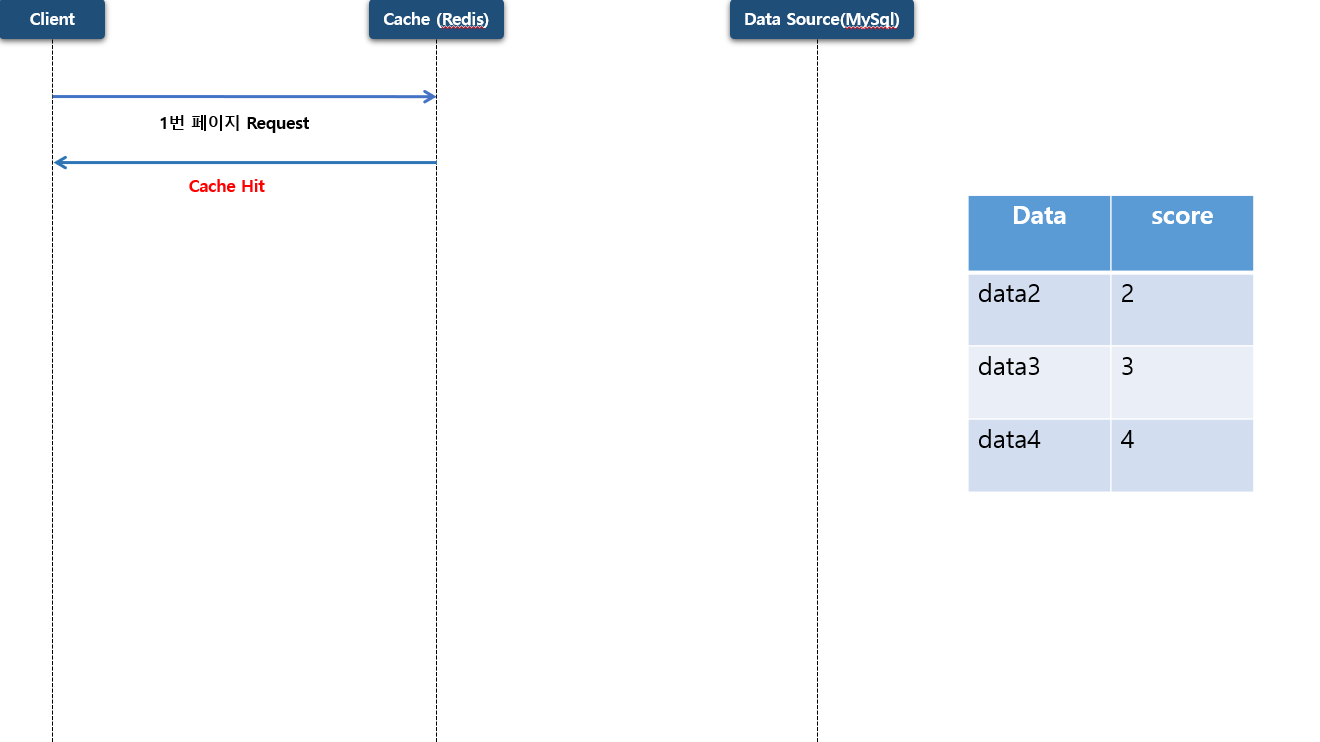
이 때 조회를 하게 된다면 네번째, 세번째, 두번째에 저장 했던 데이터를 반환 하게 됩니다.
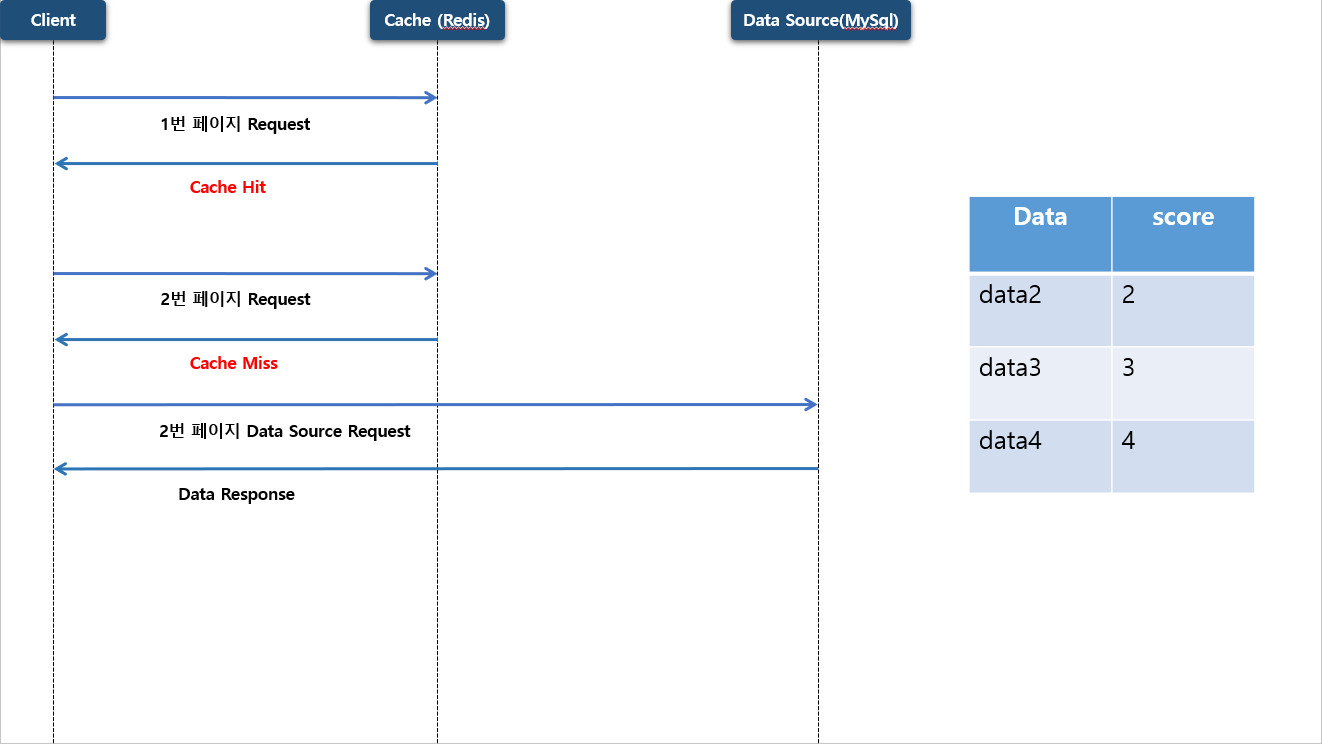
만약 사용자가 두번째 페이지를 조회 하게 되면 이때는 Cache Miss 가 발생 되면서 원본 저장소 에 있는 데이터를 조회 하게 됩니다.
Hot Key
Hot Key 는 캐시나 Redis 에서 특정 키에 요청 트래픽이 비정상적으로 집중되는 현상을 말합니다.
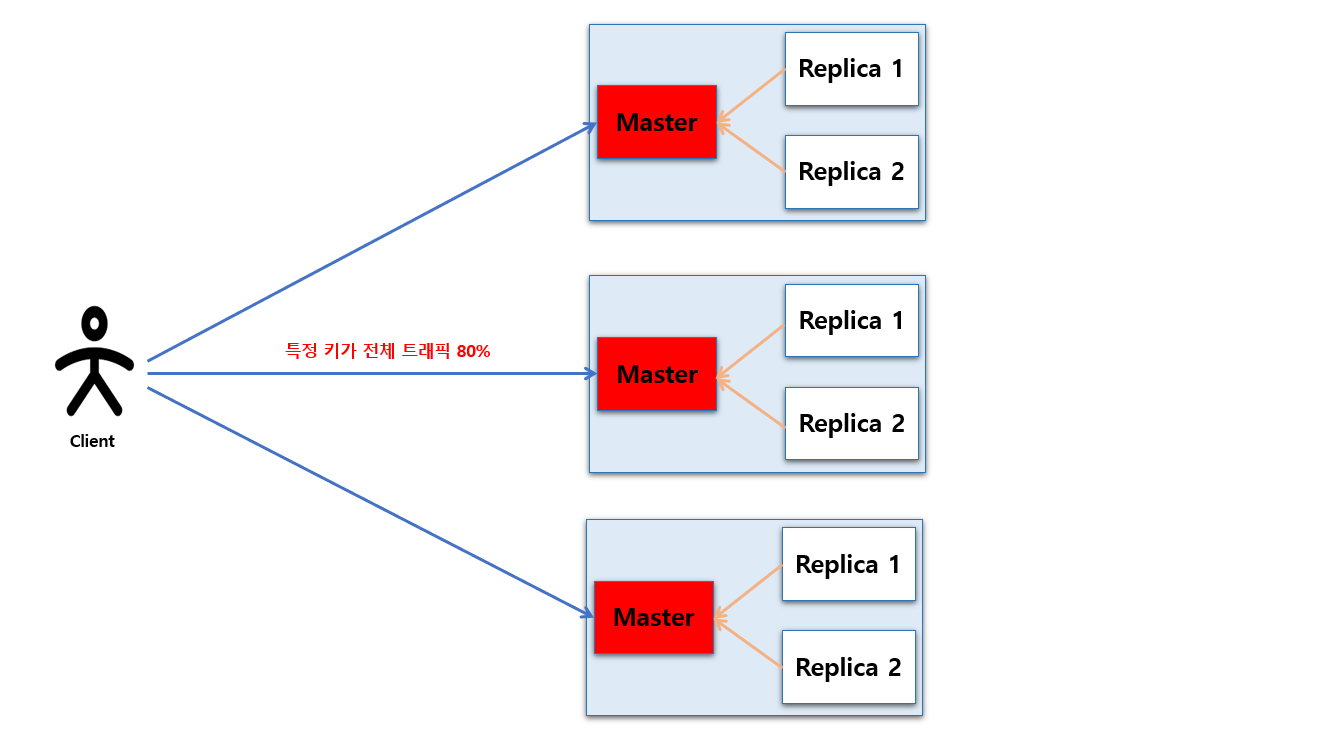
다음 그림은 Redis Cluster 로 구성되어 있는 이미지 입니다. 이렇게 Cluster 통해 분산 되어 있다 해도 특정 노드에서만 다수의 Hot Key 가 존재 한다면 해당 노드에만 부하가 증가 하게 될 것 입니다.
Application Level Sharding - Replication
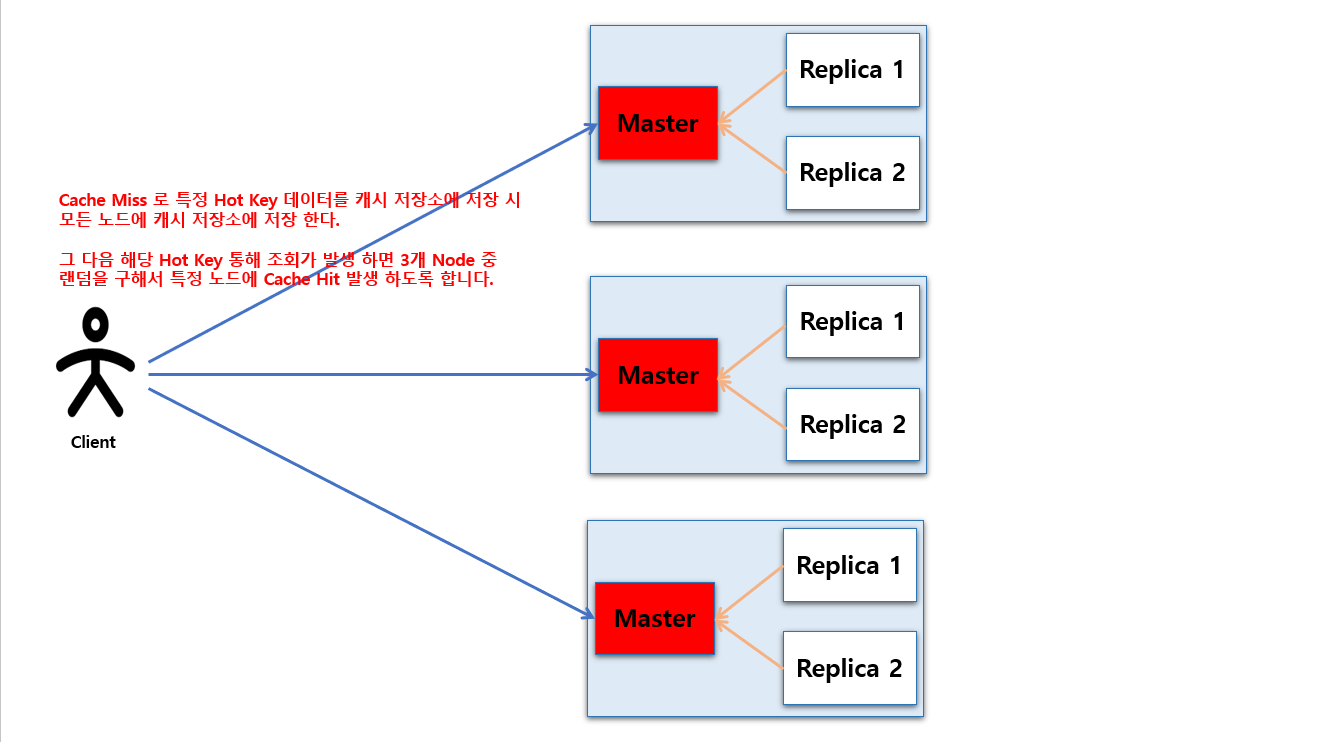
Cache Miss 로 특정 Hot Key 데이터를 캐시 저장소에 저장 시 모든 노드에 캐시 저장소에 저장 한다.그 다음 해당 Hot Key 통해 조회가 발생 하면 3개 Node 중랜덤을 구해서 특정 노드에 Cache Hit 발생 하도록 합니다.
Copyright 201- syh8088. 무단 전재 및 재배포 금지. 출처 표기 시 인용 가능.

