ElasticSearch 검색 활용기
ElasticSearch 란?
Elasticsearch 란 오픈 소스 분산, RESTful 검색 및 분석 엔진, 확장 가능한 데이터 저장소 및 벡터 데이터베이스 이다.
즉 검색 및 데이터 분석 최적화 된 데이터베이스 입니다.
협업에서는 주로 ElasticSearch 를 어떻게 사용 할까?
검색 최적화
// 이미지Elasticsearch는 수많은 데이터가 존재 하더라도 뛰어난 검색 속도를 가지고 있습니다. 그리고 오타나 동의어 기능 지원하서 유연하게 검색할 수 있는 기능을 가지고 있습니다.
지마켓, 위키백과, 당근에서Elasticsearch를 활용해 구현 되어 있습니다.데이터 수집 및 분석
// 이미지Elasticsearch는 대규모 데이터 로그를 수집 및 분석하는 데 최적화 되어 있습니다. 주로Elasticsearch는 데이터 저장을 하고,Logstash데이터 수집 및 가공 그리고Kibana는 데이터 시각화로 같이 활용해서 데이터를 수집 및 분석 합니다.
ElasticSearch 기본 용어
| MySQL | Elasticsearch |
|---|---|
| 테이블(table) | 인덱스(index) |
| 컬럼(column) | 필드(field) |
| 레코드(record), 로우(row) | 도큐먼트(document) |
| 스키마(schema) | 매핑(mapping) |
대중적으로 사용하고 있는 데이터베이스 중 Mysql 있습니다. 데이터를 등록 및 수정 삭제를 할 수 있는데요. ElasticSearch 도 마찬가지 입니다.
각각의 용어와 세부적인 특징은 틀리지만 ElasticSearchc 도 등록 및 수정 삭제 조회를 할 수 있습니다.
역인덱스 (Inverted Index) 알아보자
역인덱스(Inverted Index) 는 필드 값을 단어 마다 분해 및 쪼개서 찾기 쉽게 정리 해놓은 목록 입니다. 예시로 설명 하겠습니다.
1 | POST /musics/_create/1 |
| 토큰(token) | 도큐먼트 id |
|---|---|
| 노래 | [1, 2, 3] |
| 고백 | [1] |
| 바람 | [2, 3] |
| 리듬 | [3] |
musics 이라는 인덱스에 name 필드에 대한 역인덱스 목록 리스트 입니다.
여기서 필드값에서 추출되어서 역인덱스에 저장된 단어를 토큰 (token) 이라고 부릅니다.
이때 사용자가 노래 리듬 이라고 검색 한다고 하겠습니다. 그럼 역인덱스 을 활용해 일치 하는 단어가 많은 도큐먼트 우선으로 조회 하게 됩니다.
| 토큰(token) | 도큐먼트 id |
|---|---|
| 노래 | [1, 2, 3] |
| 고백 | [1] |
| 바람 | [2, 3] |
| 리듬 | [3] |
- id가 1인 도큐먼트 : 단어 1개 일치
- id가 3인 도큐먼트 : 단어 2개 일치
이렇게 Elasticsearch 의 자체 알고리즘으로 score(점수) 를 측정 해서 score가 높은 순 (id=3 → id=1) 으로 도큐먼트를 조회 하게 됩니다.
일반적으로 검색어와 관련성이 높으면 높을수록 score(점수)가 높게 측정 됩니다.
TF (Term Frequency) - IDF (Inverse Document Frequency)
TF (Term Frequency) 단어 빈도
TF(term frequency) 단어 빈도는 특정한 단어가 특정 문서 내에 얼마나 자주 등장 하는 지를 나타내는 값 입니다. 즉 TF 값이 높으면 문서 내에 흔하게 등장 한다는 의미 입니다.
어플레이즈 힘내자, 어플레이즈 가즈아, 어플레이즈 화이팅
| 토큰(token) | TF |
|---|---|
| 어플레이즈 | 3/6 |
| 힘내 | 1/6 |
| 가즈아 | 1/6 |
| 화이팅 | 1/6 |
해당 문장에서 단어 갯수는 총 6개가 존재 합니다. 어플레이즈 는 문장에서 총 3번 출현 했습니다. 그럼 3/6 이 되고 그외 단어는 1/6 이 됩니다.
이렇게 보았듯이 어플레이즈 는 해당 문장내에서 가장 중요한 단어라고 할 수 있겠습니다.
하지만 TF 는 치명적인 단점이 있습니다. 어떤 경우에는 흔하게 등장하는 단어가 중요하지 않은 단어일수도 있습니다.
우리는 개발자 입니다 우리는 기획자 입니다 우리는 디자이너 입니다
| 토큰(token) | TF |
|---|---|
| 우리 | 3/9 |
| 입니다 | 3/9 |
| 개발자 | 1/9 |
| 기획자 | 1/9 |
| 디자이너 | 1/9 |
해당 문장에서는 단어 갯수는 총 9개 입니다. 여기서 우리 하고 입니다 라는 단어가 공동 1등으로 총 각각 3번 출현 했습니다. 사실 느껴지겠지만 해당 문장에서 가장 중요한 단어는
우리, 입니다 단어가 아닙니다. 즉 이렇게 TF 통해 어떤 문장 경우 가설이 틀렸다는 의미가 됩니다. 불용어와 같은 단어 빈도수가 높아서 점수를 많이 측정 되면 오히려 의도 했던 방향과 다른 전개로 가게 됩니다.
이런 케이스를 개선 하기 위한 것이 TDF (Inverse Document Frequency) 입니다. 어느 문장에서는 자주 출현 하는 단어를 패널티를 부여 하기 위한 것 인데요.
A. document : 우리 어플레이즈 힘내자 어플레이즈 가즈아 어플레이즈 화이팅
B. document : 우리는 개발을 좋아 한다.
| word | TF | IDF | TF * IDF | ||
|---|---|---|---|---|---|
| A | B | A | B | ||
| 우리 | 1 / 7 | 1 / 4 | Log(2 / 2) = 0 | 0 | 0 |
| 어플레이즈 | 3 / 7 | 0 | Log(2 / 1) = 0.3 | 0.12 | 0 |
| 힘내자 | 1 / 7 | 0 | Log(2 / 1) = 0.3 | 0.04 | 0 |
| 가즈아 | 1 / 7 | 0 | Log(2 / 1) = 0.3 | 0.04 | 0 |
| 화이팅 | 1 / 7 | 0 | Log(2 / 1) = 0.3 | 0.04 | 0 |
| 개발 | 0 | 1 / 4 | Log(2 / 1) = 0.3 | 0 | 0.075 |
| 좋아 | 0 | 1 / 4 | Log(2 / 1) = 0.3 | 0 | 0.075 |
| 한다 | 0 | 1 / 4 | Log(2 / 1) = 0.3 | 0 | 0.075 |
이렇게 역문서 빈도 (Inverse Document Frequency), 전체 문서에서의 희귀도 통해서 단어가 특정 문서에서 얼마나 중요하게 작용하는지를 나타낼 수 있도록 도와줍니다.
애널라이저 (Analyzer) 알아보기
1 | POST /musics/_create/1 |
| 토큰(token) | 도큐먼트 id |
|---|---|
| 노래 | [1, 2, 3] |
| 고백 | [1] |
| 바람 | [2, 3] |
| 리듬 | [3] |
앞써 각각의 문장을 토큰 (token) 으로 분리 해서 역인덱스 (Inverted Index) 로 저장 한다고 설명 했습니다. 이 과정에서 문자열을 토큰 (token) 으로 분리 및 변환 하는 과정을 애널라이저 (Analyzer) 이라고 합니다.
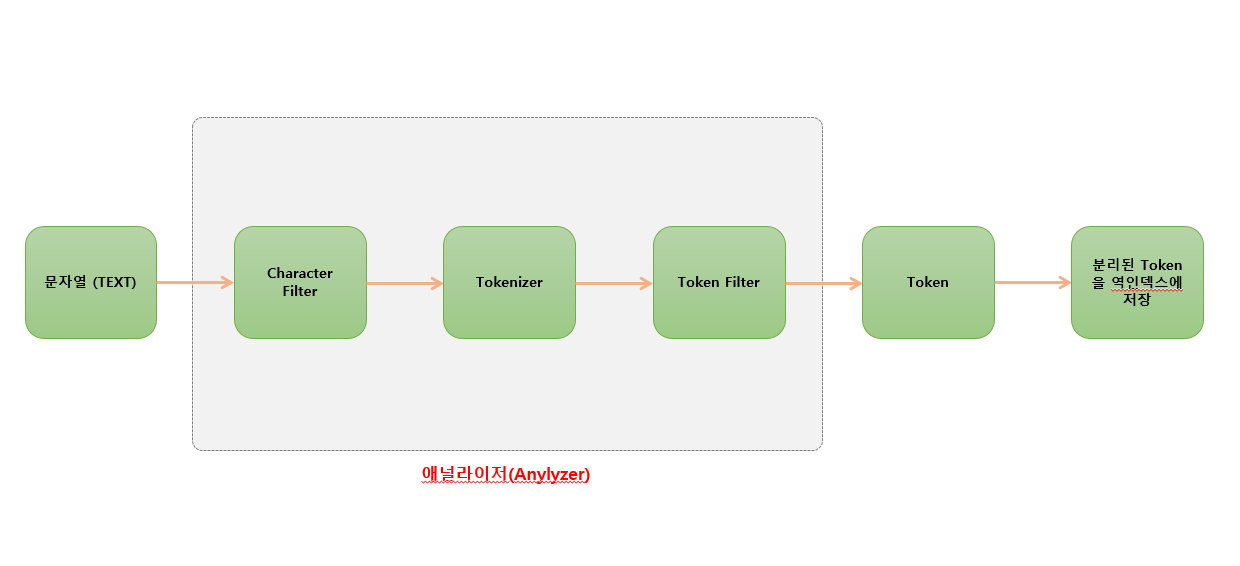
의미 없이 문자열을 가지고 간단하게 단어 단위 로만 자르는 게 아니라 애널라이저 (Anylyzer) 가 여러 가지의 작업을 거쳐서 토큰으로 분리 합니다.
애널라이저 (Analyzer) 는 내부적으로
- 캐릭터 필터 (Character Filter)
- 토큰나이저 (Tokenizer)
- 토큰 필터 (Token Filter)
이렇게 3가지 활용해 문자열을 토큰으로 변환 합니다.
캐릭터 필터 (Character Filter)
캐릭터 필터 (character filter) 는 문자열을 토큰으로 분활 하기전 문자열을 다듬는 역할을 하게 됩니다. 다양한 필터 종류가 존재 하는데 대표적으로 html_strip 필터가 있습니다.
1 |
|
토큰나이저 (Tokenizer)
토큰나이저 (tokenizer) 는 문자열을 토큰으로 분활 하는 역할을 합니다. 대표적으로 Elastic Search 에서 Default 토큰나이저인 Standard Tokenizer 가 있습니다.
1 | # Standard Tokenizer 예시 |
토큰 필터 (Token Filter)
토큰 필터 (token filter) 는 Tokenizer 통해 분활 된 각각의 토큰을 다듬는 역할을 하게 됩니다. 이 역시 다양한 종류의 필터가 존재 하고, 여러 개의 필터를 적용 시킬 수 있습니다.
1 | # lowercase 필터 적용 (소문자 변환) |
match 쿼리 알아보기
match 쿼리는 검색 키워드가 포함된 데이터를 조회하고 싶을 때 사용 됩니다. 특징적으로 데이터 타입 중 text 타입 필드 에서만 활용이 가능 합니다.
1 | PUT /musics |
musics 이라는 인덱스를 생성 하고 음악 정보를 데이터 저장 합니다.
1 | GET /musics/_search |
text 타입 필드는 match 쿼리를 활용해 검색을 합니다. 하지만 text 타입이 아닌 필드 에서는 match 쿼리를 사용 하면 안됩니다.
term, terms 쿼리 알아보기
특정 값과 정확하게 일치하는 데이터를 조회하고 싶을 때 사용 됩니다. 예를들어 Mysql 데이터 베이스에서
1 | SELECT * FROM musics WHERE name = '아이유'; |
해당 쿼리 경우 name 필드에 아이유 라는 키워드가 정확하게 매칭 되는 데이터만 가져오는 것 처럼 ElasticSearch 에서도 term, terms 쿼리를 이용해 특정 값과 정확하게 일치하는 데이터를 조회 할 때 사용 됩니다.
1 | # 매핑 등록하기 |
term, terms 쿼리를 사용하기 위해서는 mapping 시 keyword 데이터 타입으로 저장 해야 합니다.
1 | # 도큐먼트 저장 |
1 | # `term` 쿼리를 이용해 검색 하기 |
terms 쿼리 - 여러 개의 값 중 하나라도 일치하는 도큐먼트 조회 하기
terms 쿼리는 여러 개의 값 중 하나라도 일치하는 모든 도큐먼트를 조회 합니다. 예를들어 Mysql 에서 In 절 이용해 조회 하는 기능과 비슷하다고 생각 하면 됩니다.
1 | GET /musics/_search |
filter, must 쿼리 알아보기
여러 개의 조건을 동시에 만족하는 데이터를 조회하고 싶을 때
SELECT * FROM musics WHERE artist = “아이유” AND music_name = "좋아요"과 같이 2가지 이상의 조건을 만족 할때 검색 할 수 있도록 해야 하는 상황이 있습니다. 아래와 같이 작성하면 되지 않을까라고 생각할 수 있는데요.
1 | GET /musics/_search |
1 | "[term] query doesn't support multiple fields, found [artist] and [music_name]" |
이렇게 에러가 발생 됩니다. Elastic Search 에서는 term 쿼리 사용시 두개 이상 필드를 조합해서 사용 할 수 없습니다. 이렇게 두개 이상 필드 조건을 만족 할려면 bool 쿼리를 사용 해야 합니다. bool 쿼리 경우 크게 4가지 기능이 존재 하는데요.
- must : SQL문 에서의
AND역할을 함 - filter : SQL문 에서의
AND역할을 함 - must_not : SQL문 에서의
NOT역할을 함 - should : 조건을 만족하면 좋고, 아니면 말고.
이 중에서 2가지 조건을 전부 만족시키는 데이터를 조회하기 위해서 must와 filter에 대해 알아야 합니다.
1 | GET /musics/_search |
이렇게 bool 쿼리에서 filter 사용하면 됩니다. 그럼 filter 아닌 must 는 어떤 경우에 사용 될까요? 그리고 filter 하고 차이점은 무엇일까요?
filter vs must
filter와 must 큰 차이는 filter 는 score(점수) 에 영향을 주지 않고 must는 score(점수)에 영향을 준다는 점 입니다. 여기서 score(점수)는 검색을 할 때 관련도가 얼마나 높은 지를 나타내는 수치 입니다.
score(점수)가 활용되는 대표적인 쿼리는 match 입니다. score(점수)를 활용해 관련도가 가장 높은 도큐먼트 순으로 우선적으로 조회 하게 됩니다. 즉 정확하게 일치하지 않아도 (score(점수)) 도큐먼트를 조회 하게 됩니다.
그에 반면 term 쿼리는 조건을 정확하게 일치 시켜야지 도큐먼트를 조회 하게 됩니다. 즉 score(점수)를 사용하지 않습니다. filter와 must의 사용 용도는 score(점수)에 영향을 주는 쿼리인지 아닌지로 구분해서 사용해야 합니다.
filter:score(점수)와 상관없는 쿼리인 경우term쿼리 사용must:score(점수)와 상관있는 쿼리인 경우match쿼리 사용
Copyright 201- syh8088. 무단 전재 및 재배포 금지. 출처 표기 시 인용 가능.

