예제 소스 코드
이번 블로그에 사용되는 코드는 아래 링크 통해 확인 할 수 있습니다.
Flink Server
https://github.com/syh8088/flink_study/tree/main/flink_space_congestion/flink_server
Flink 이용해서 실시간 데이터 스트림 처리 해보기
Flink 는 무엇인가?

Flink 는 독일어로 ‘민첩함’ 민첩함 상징으로 빨간 다람쥐 통해 로고로 사용되고 있습니다.
처음에는 베를린 TU 대학교에서 시작된 아파치 프로젝트에서 2011년에 Stratosphere 0.1 릴리즈를 시작하였으며 2015년에는 Apache Flink 0.9 버전으로 릴리즈 하게 되었습니다.
현재는 세계 유명 대기업 (우버, 알리바바, 넥플릭스) 에서 대규모 스트림 처리를 하기 위해 Flink 를 사용 하고 있습니다.

https://flink.apache.org/ 에 접속하시면 첫화면에 Flink 에 대한 간단하게 소개하는 글이 있습니다.
stateful computations over unbounded and bounded data streams.
상태가 있는 스트림 처리 하는데 있어서 unbounded (무한한 데이터) 와 bounded (유한한 데이터) 를 모두 데이터 처리가 가능 한다는 점 입니다.
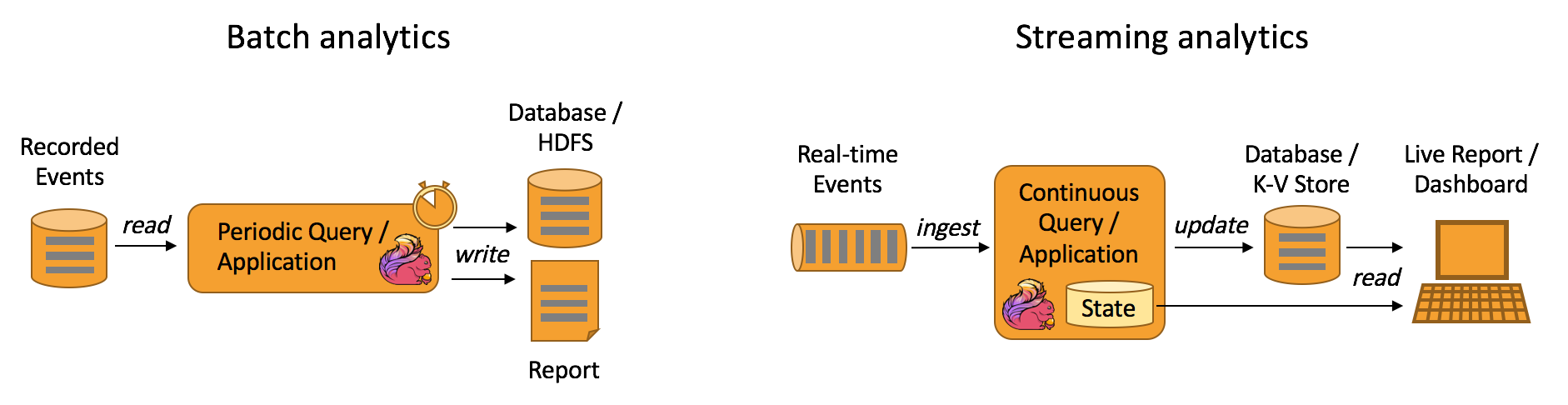
즉 배치 처리와 스트림 데이터 처리를 모두 가능하다는 말이 됩니다.
여기서 배치 처리란 기존에 어디간 저장되어 있는 데이터를 가져와서 주기적으로 처리 후 가공된 데이터를 또 다른 어딘가에 저장 하는 프로세스이고
스트림 처리란 실시간 으로 데이터 이벤트가 발생되는 상황에 Flink 가 발생된 이벤트 데이터를 가지고 분석 후 실시간으로 또 다른 어딘가에 저장 하는 프로세르 라고 생각 하시면 됩니다.
at in-memory speed and at any scale.
데이터 규모 스케일이 상관 없이 in-memory 속도 수준으로 처리가 가능 하다고 소개 되어 있습니다.
초당 수천만으로 발생한 이벤트 처리를 throughput 제공 하고 1초 미만 latency 제공 하고 있습니다. 그리고 수십 terabyte state 관리 및 복구가 가능 합니다.
상태가 있는 스트림 처리 (Stateful Stream Processing) 개념 소개
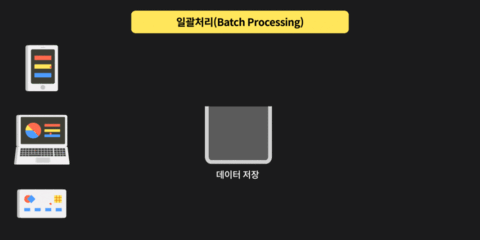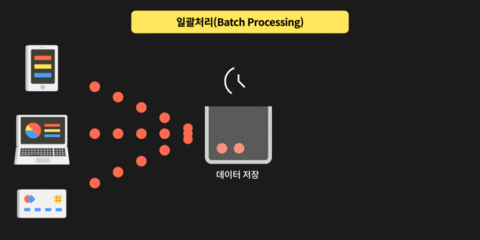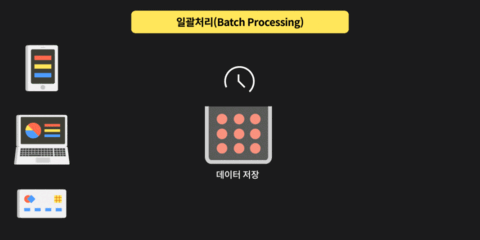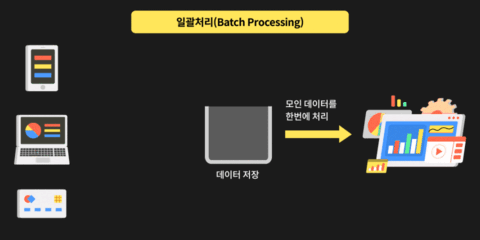
상태가 있는 데이터 스트림 설명하기전에 상태가 없는 데이터 스트림을 먼저 설명 하도록 하겠습니다.
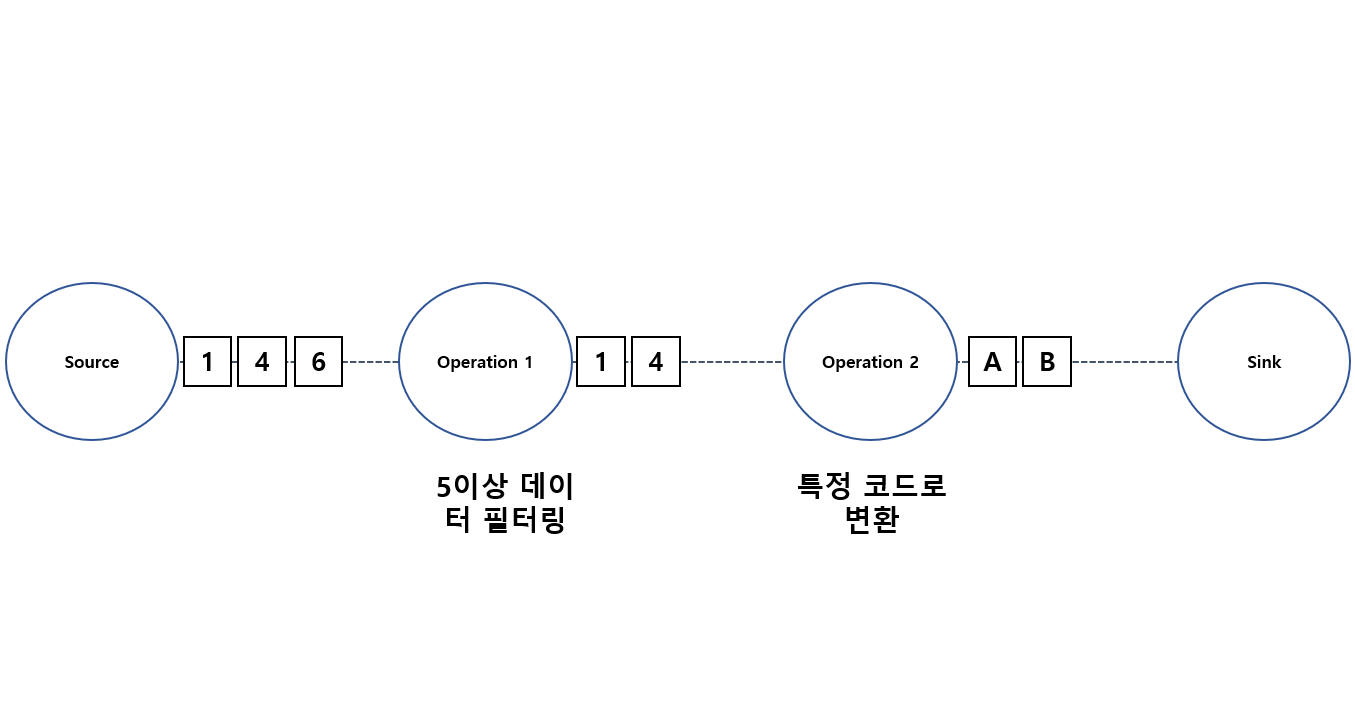
Source 로부터 1, 4, 6 데이터를 받는 과정에서 1번 오퍼레이션에서는 5이상 데이터를 필터링 한다고 하면 1, 4 데이터만 필터링 하게 될 것 입니다.
그런 후 각각의 데이터들을 특정 코드로 변환해서 Sink 하게 되는 과정이 단순히 각각 요청 받는 데이터를 미리 구현한 오퍼레이션 통해 데이터를 필터링 하고 변환 하는 과정
즉 상태가 없는 스트림 처리라고 생각 하시면 됩니다.
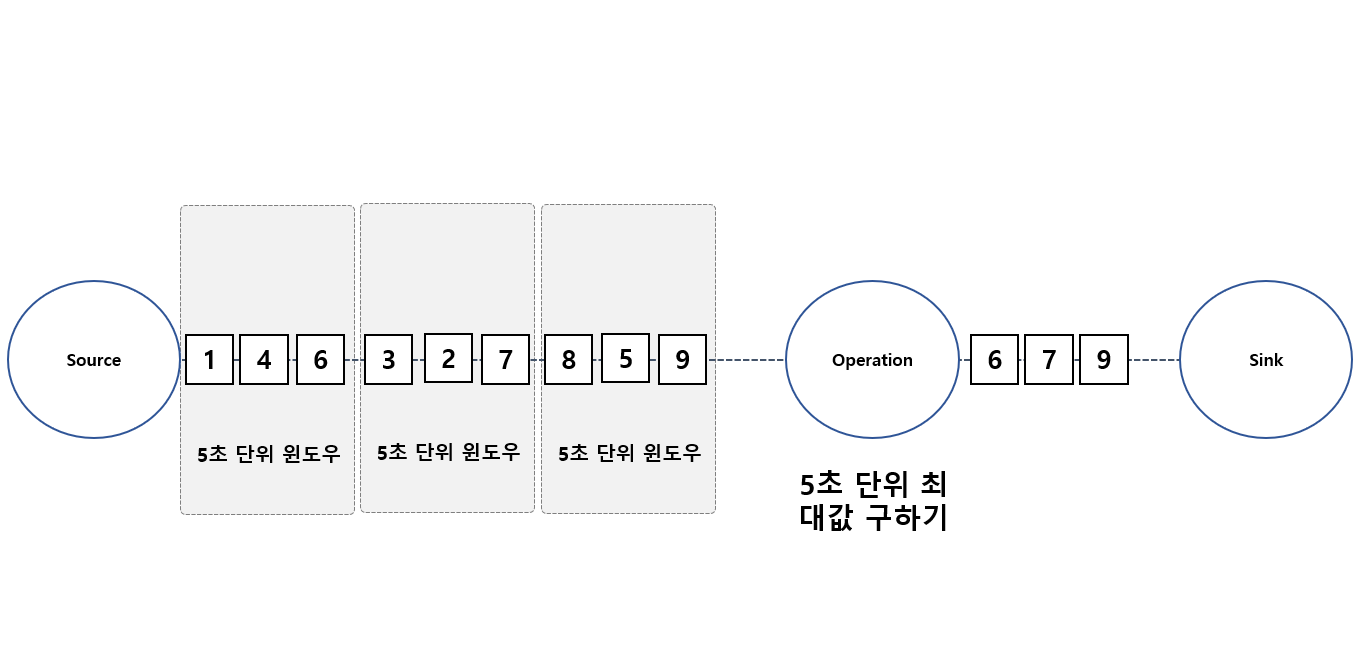
그럼 상태가 있는 데이터 스트림 처리 경우에는 연속적으로 (실시간으로) 데이터 스트림 처리하는 과정에서 5초 단위로 윈도우로 설정 하고 각각의 윈도우를
특정 오퍼레이션에 도달 했을때 특정 윈도우에서 가장 큰수를 추출 하고자 할려면 요청 받은 데이터를 기억해서 연산 후 처리 하게 됩니다.
각 윈도우에서 처리가 완료되면 기억했던 가장 큰 숫자를 Sink 로 보내지게 됩니다.
이렇게 분단위 및 시간 단위로 설정해서 이벤트를 aggregation 하고 중간 aggregation 결과를 상태값 기억하고 처리시 활용 할 수 있습니다.
Flink 는 이러한 상태가 있는 데이터를 일관성 유지하면서 데이터 처리가 가능하기 때문에 여러 방면으로 활용이 가능 합니다.

Flink 는 어떻게 State 를 관리를 할까?
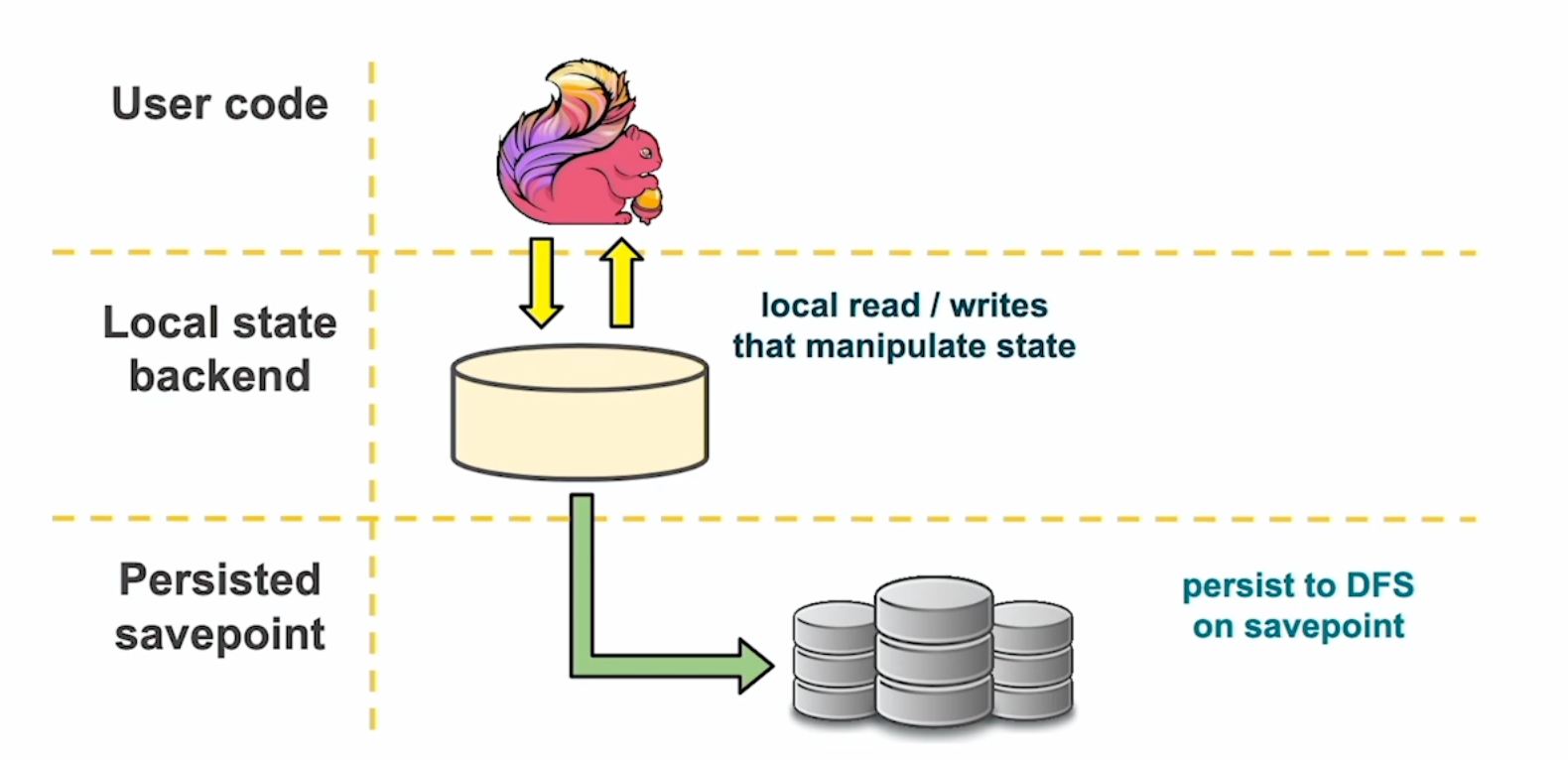
User code 에서 특정 값을 State 하겠다고 하면 Flink 는 주기적으로 Local state backend 에서 내려 쓰게 됩니다. 이러한 과정을 Checkpoint 라고 합니다.
사용자가 지정한 주기마다 정해진 주기 단위로 중간 연산값들을 스냅샵 통해 내려 받게 되고, 만약 연산 하는 과정에서 문제가 있어서 복구 해야 하는 상황이 발생 되면 저장된 Checkpoint 를 복구 해서 다시 연산을 이어지게 됩니다. (Consistency 유지)
특정 시점에 분산 되어있는 전역 state 에 대한 snapshot. HDFS, S3등에 저장. Flink 업그레이드, 코드 변경 등의 작업 시 사용자가 직접 활용 할 수 있습니다. 이를 Savepoint 이라고 합니다.
Flink 사용 예시
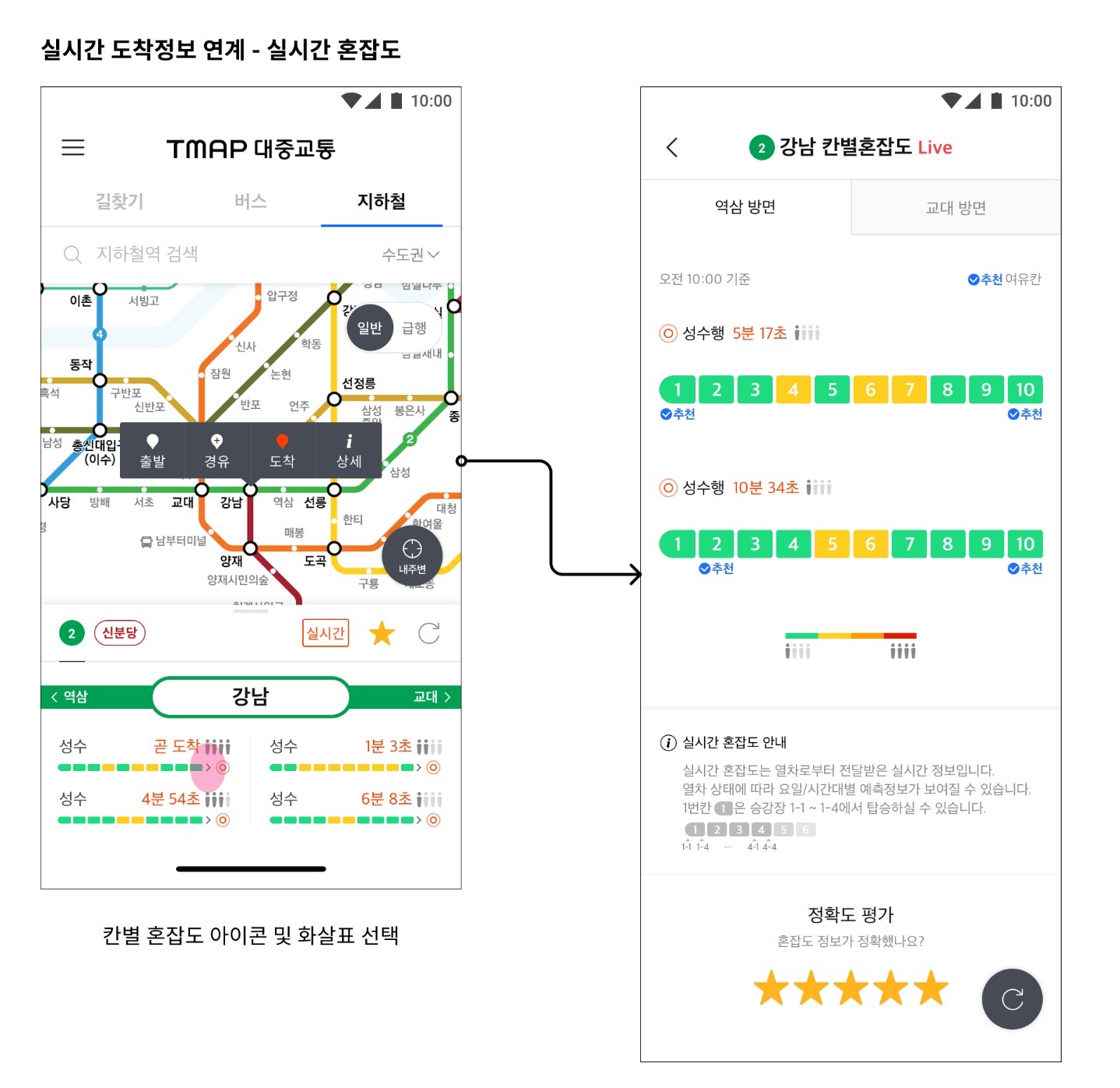
TMAP 앱에서 활용되고 있는 예시 하나 설명 하겠습니다. 지하철 실시간 혼잡도 기능인데요. 열차의 칸마다 실시간으로 혼잡도를 사용자에게 보여주는 기능이고 이러한 기능을 구현하기 위해서는 실시간 데이터 스트림을 처리 하기 위해 실제로 Flink 로 활용해서 구현 하고 있다고 합니다.
이렇게 실시간으로 정해진 단위로 어떠한 값들을 연산 및 처리 하기 위해서 Flink 를 많이 활용 되고 있습니다.

클라우드 모빌리티 존(Cloud Mobility zone)은 모빌리티 디바이스와 서비스, 인프라가 하나의 플랫폼으로 연결된 이동 생태계를 구현한 공간으로, 현대차그룹의 소프트웨어 모빌리티 비전을 실제로 체험할 수 있는 공간이다.
Flink 클러스터 구조
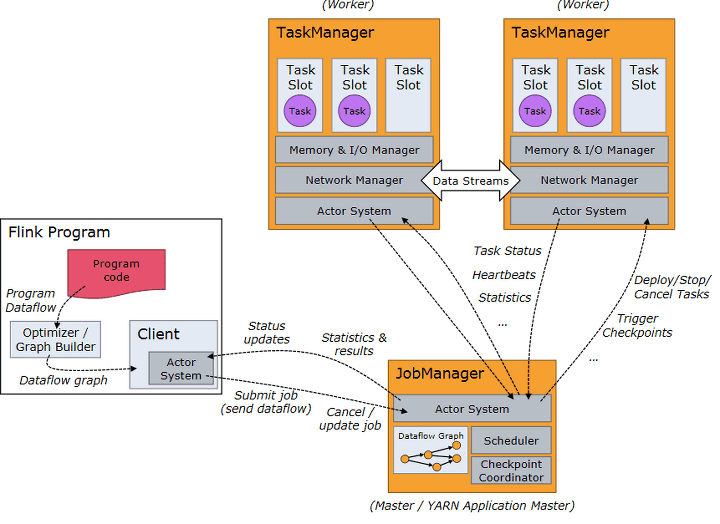
Flink 클러스터 구조 이미지 입니다. Flink 를 설치 하고 클러스터를 띄우게 되면 크게 2가지 종류의 프로세스를 띄우게 된다고 생각하시면 되는데요.
- JobManager
JobManager는 Flink 클러스터에서 마스터 노드의 역할을 수행하며, 여러 핵심 기능을 제공합니다.
- 클러스터 내 리소스 할당/해제
- Task 스케쥴링
- Checkpoint 관리
- Recovery 관리
- TaskManager
Flink 클러스터 내에서 실제 데이터 처리 작업을 수행하는 컴포넌트입니다.TaskManager는 클러스터의 워커 노드 역할을 하며,JobManager로부터 할당받은 작업(Task)을 실행합니다. 각TaskManager는 여러 태스크를 병렬로 처리할 수 있는 하나 이상의 슬롯을 가집니다.
Flink 의 시간 개념 알아보기
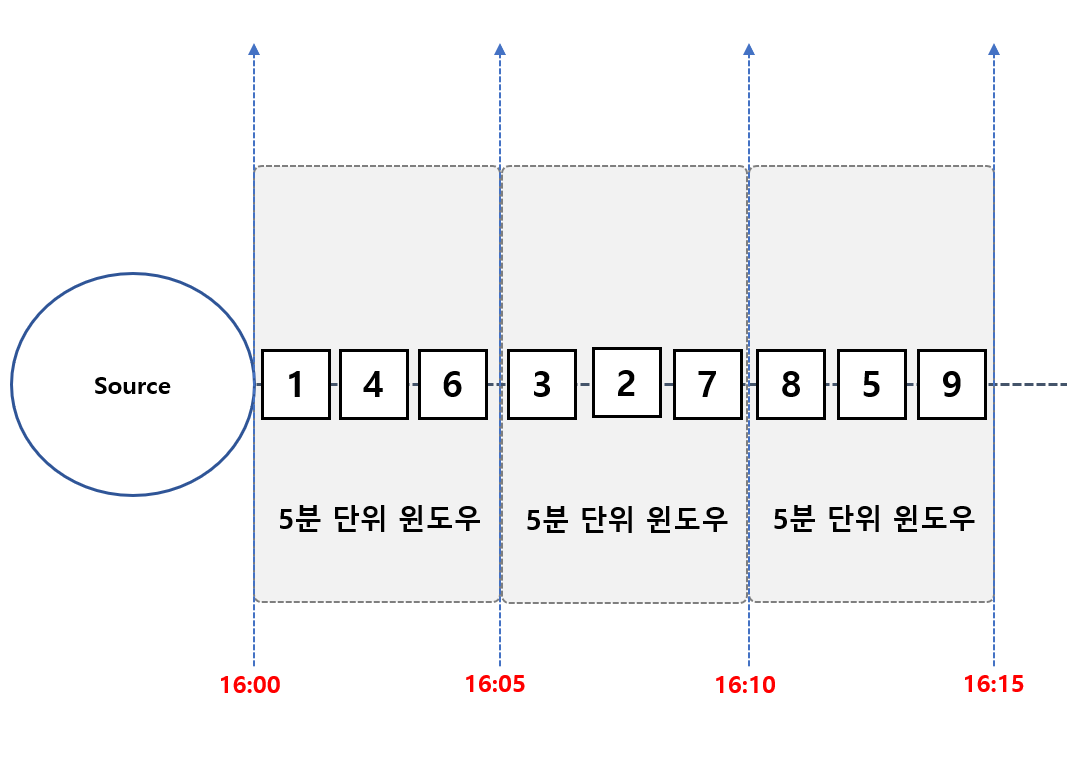
Stream Processing 에서 (Batch Processing 틀리게) 시간의 개념을 어떻게 설정 하느냐에 따라 최종 연산 결과가 달라질 수 있습니다. 그러니깐 Stream Processing 는 Real Time (실시간) 상황에서 연속적으로 데이터가 들어오는 상황에서 시간의 개념을 어떻게 지정 하느냐에 따라 연산 처리가 각각 달라질 수 있습니다.
바로 상단 이미지를 보시면 5분 마다 윈도우 박스를 설정하는데 저 시간을 어느 시점에 설정 할 것인지 그러니깐 Flink Server 에 데이터를 도착 할 시점에 시간을 설정 할 것인지 아니면 Flink Server 에 데이터 도착 이전에 실질적으로 이벤트가 발생 한 시점에 시간을 설정 할 것인지에 따라 달라 질 것 입니다.
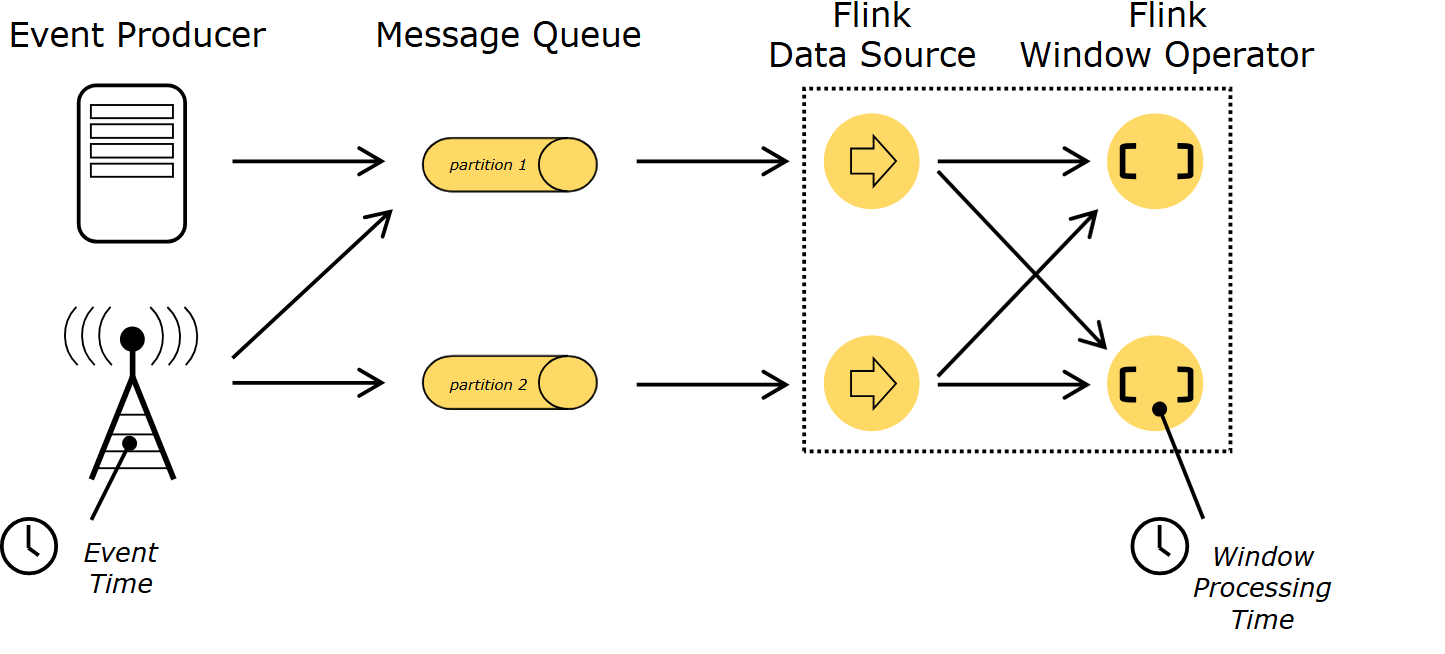
Flink 에서 시간의 설정 종류 방식을 크게 2가지 방식이 있습니다.
- Processing Time
- Event Time
각각 하나씩 알아보도록 하겠습니다.
Processing Time
Processing Time 는 연산을 실행되는 머신의 시스템 시간 입니다. 예를들어 5초 마다 윈도우 박스를 설정하고 각각의 박스권 내에서 최대값을 구할때 시간을 연산이 실행되는 머신의 시간 기준으로 설정 하는 것이 Processing Time 입니다.
장점으로는 시간 설정이 간단하기 때문에 성능상 우수하지만 단점으로는 시간을 머신의 시간 기준으로 설정 하기 때문에 문제가 발생 될 수 있습니다. 즉 각각의 데이터들을 Flink Server 로 전달하는 과정에서 항상 동일한 시간내에 도착 하지 않기 때문에 네트워크 불안정한 상태라면 늦게 도착 되면서 연산 하는데 결과가 달라질 수 있습니다.
Event Time
Event Time 는 개별 각각의 이벤트가 발생한 시점의 이벤트가 발생한 시스템의 시간 입니다. 즉 최초 이벤트가 발생한 시점 동시에 이벤트 발생된 시간 데이터를 포함해서 Flink Server 로 전송 되기 때문에 각각의 데이터가 Flink Server 로 들어왔을때 이미 시간 데이터를 포함해서 수신 하게 됩니다.
장점으로는 각각의 이벤트가 발생되고 Flink Server 로 전송 하는 과정에서 네트워크 불안정한 환경이라도 이미 미리 이벤트 시간을 설정한 상태이기 때문에 이론적으로 동일한 연산 처리가 가능 하게 됩니다. 데이터를 재처리시에도 항상 동일한 연산 결과를 보장 하는 것이 특징 입니다.
단점은 Event Time 으로 시간 설정시 특정 이벤트가 Flink Server 로 전송하는 과정에서 늦게 도착 하는 케이스 경우 이때 언제까지 기다릴 것인가? 즉 실시간 처리를 보장 받기 위해 무작정 끝까지 기다릴수 없는 상황에서 언제까지 기다릴 것인가 라는 고려 해야 될 상황이 있습니다.
Processing Time VS Event Time
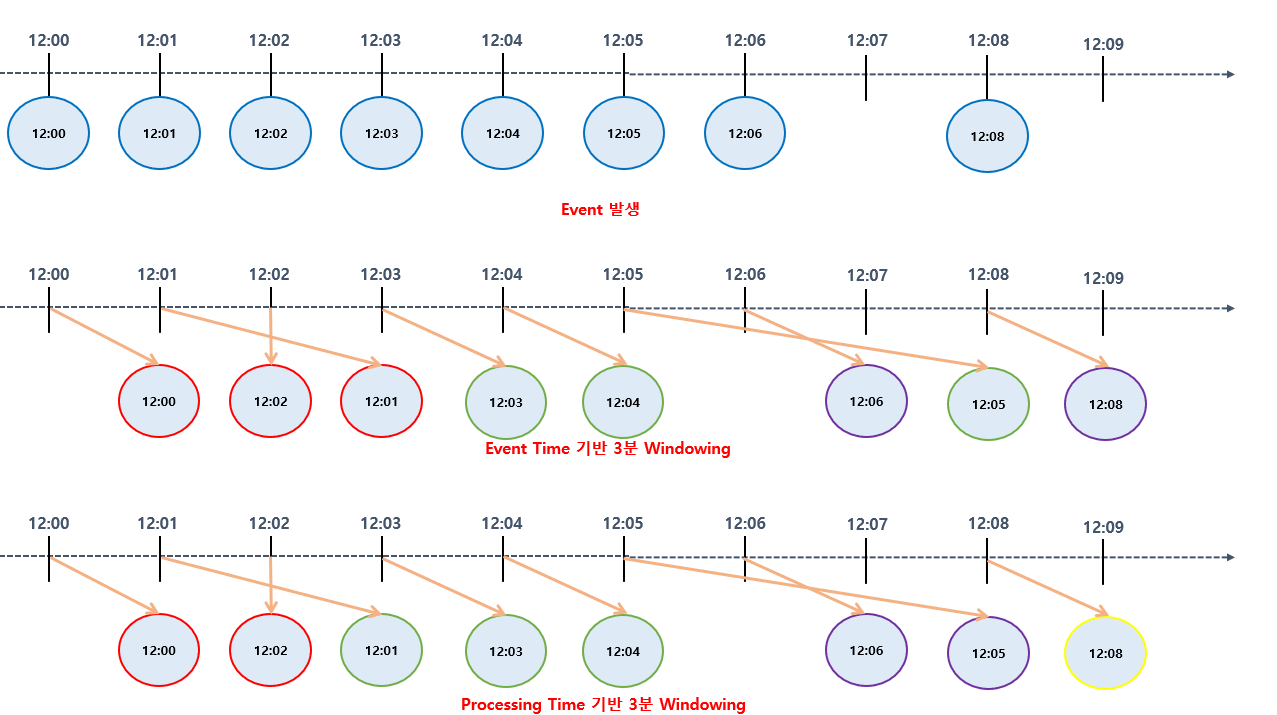
앞써 이야기 한대로 Flink 에서 어떤 시간 개념을 설정 하느냐에 따라 Window 영역 구간 설정이 달라집니다. 즉 연산 처리가 달라지는데요. 예시로 설명 하도록 해보겠습니다.
12:00 부터 12:09 까지 시간이 흐르는 상태에서 이미지 최상단은 이벤트가 몇시 몇분에 발생 (Producing Machine 에서 발생한 최초 이벤트 시간) 했는지 표시 하고 있습니다.
여기서 Event Time 기준으로 설정 하게 된다면 최초 Producing Machine 에서 발생한 시간 기준으로 Window 영역 구간을 설정 하기 때문에 12:00 ~ 12:02 시간에 발생한 이벤트가 Flink Server 에 각각 12:01, 12:03, 12:02 에 도착 하더라도 최초 이벤트 발생한 시간 기준으로 설정 하기 때문에 같은 빨간색 구역으로 취급 하게 됩니다.
반면 Processing Time 기준으로 설정 하게 된다면 Flink Server 에 도착한 시점 부터 시간 설정 기준으로 Window 영역 구간을 정하기 때문에 12:01, 12:02 에 각각 도착한 시간 기준으로 빨간색 구역으로 취급 하게 됩니다.
Watermark 설정 하기
Event Time 기반으로 Data Processing 처리시 해결해야 할 문제가 있습니다. Event Time 기준으로 데이터 처리시 Event Time 이 얼마나 흘렀는지를 어떻게 판단 할 것인가? 인데요. 즉 Flink Server 내에서 특정 Operation 을 수행 하는 시스템에서는 현재 시간이 몇시 몇분인지 알 수가 없다는 점 입니다.
예를들어 3분 단위로 Windowing 구역을 설정 할때 어떻게 3분이 흘렀는지 판단하고 Window 구역을 닫을 것 인가 입니다. Event Time 경우 데이터를 처리하는 시스템의 시간과 별개로 결정 되는 부분이기 때문에 어려문 문제 입니다.
이러한 문제를 해결 하기 위해서는 Flink 에서는 Watermark 라는 기능을 활용 하게 됩니다.
Watermark 란 Stream Processing 에서 Event Time 의 흐름을 측정하기 위한 매카니즘 입니다. 데이터 스트림 하는 과정에서 데이터가 흘러가는데 데이터 중간에 Watermark 도 함께 전송 하게 됩니다. Watermark 는 특별한 데이터가 있는 것이 아니고 Timestamp(t) 를 가지고 있습니다.
Flink 에게 Watermark 인 Timestamp(t) 을 알려주면서 현재시간을 알려줍니다. 현재 시간을 알려주면서 이를 근간으로 Flink 는 Window 영역 구간을 설정 할 수 있게 됩니다.
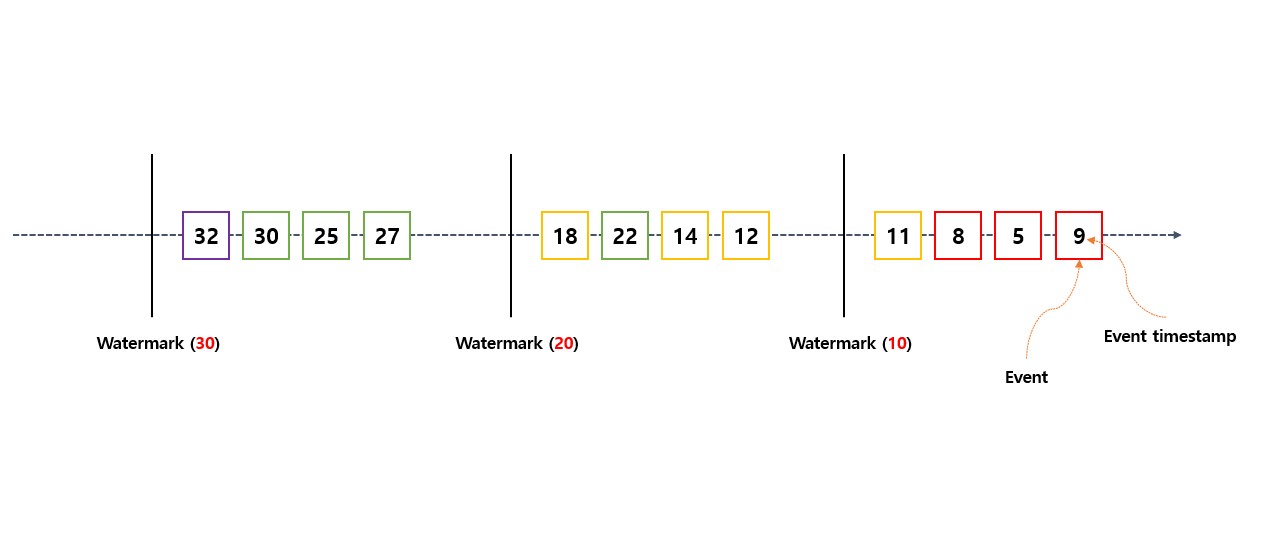
실시간 Stream Processing 처리 과정에서 Watermark (10) 만나게 된다면 지금까지 Event 데이터 들을 받았던 것 중에 Event timestamp 값이 10 이하 인 것만 추출해서 Windowing 구역을 설정 하게 됩니다. 다시 반복해서 데이터 스트림 받는 과정에서 Watermark (20) 을 만나게 된다면 지금까지 Event 데이터 들을 받았던 것 중에 Event timestamp 값이 20 이하 인 것만 추출해서 Windowing 구역을 설정 하게 됩니다.
실습 해보기
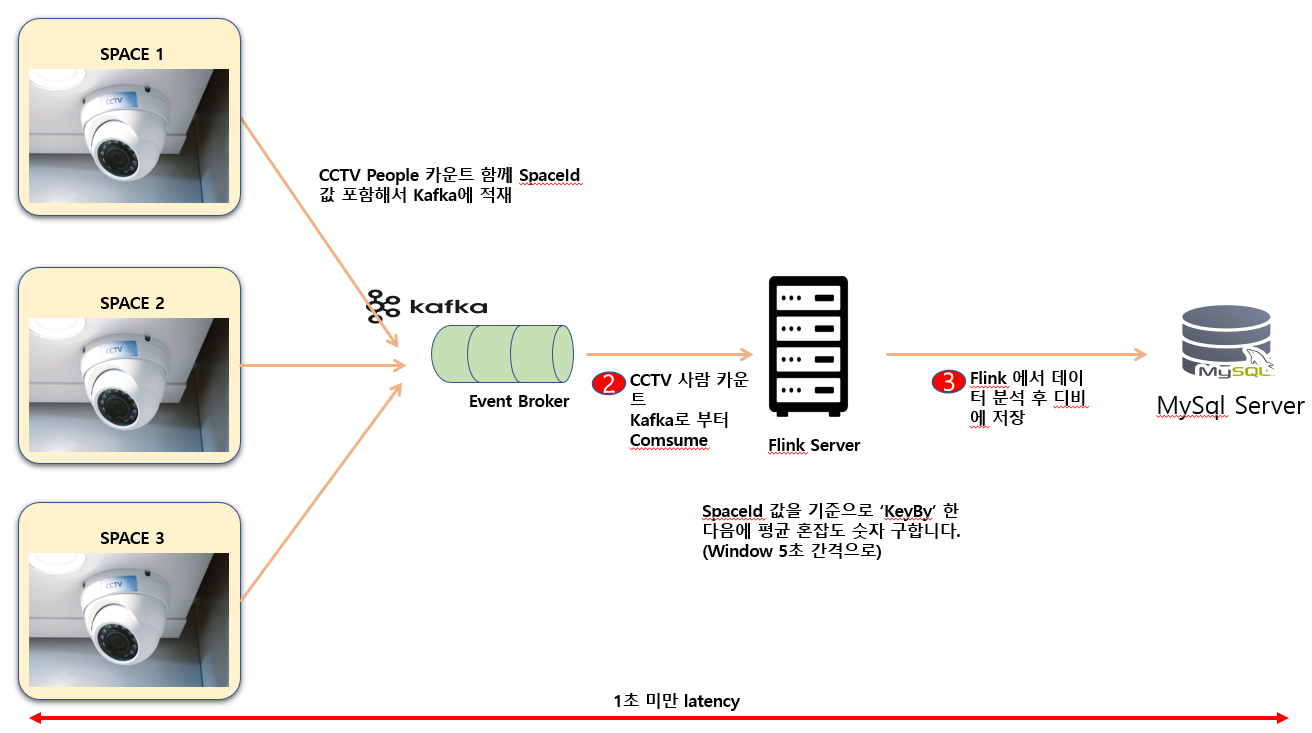
실습 하고자 하는 내용을 설명 하겠습니다. 우선 CCTV 에 설치된 구역을 SPACE 로 지칭 하겠습니다. 각각의 SPACE 에서 CCTV 통해 사람의 카운트를 추출 해서 Kafka로 전송하게 됩니다.
그런 다음 Consume 하는 Flink 서버는 spaceId 값과 실시간으로 CCTV 로 영상 촬영된 사람의 카운트 값을 받아서 spaceId 값 기준으로 KeyBy 하게 됩니다.
15초 간격으로 Tumbling Window 방식으로 평균 사람의 카운트 값을 추출해 DB 에 저장 하도록 하겠습니다.
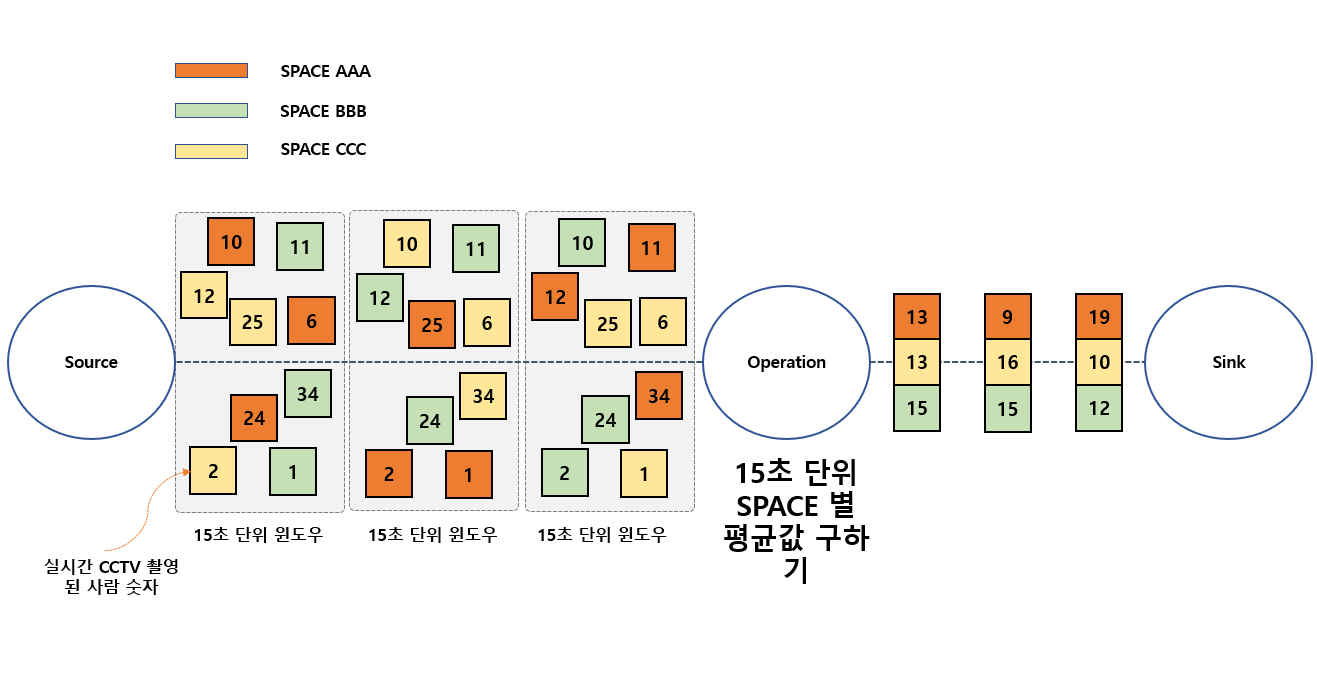
실시간으로 CCTV 로부터 사람 숫자를 계산한 값 포함해서 촬영된 SPACE_ID 값 함께 Kafka 서버로 전송 하게 됩니다. 그럼 Fink 서버는 Kafka 서버로 전송된 값을 consume 하게 되고 15초 윈도우 간격으로 SPACE 값 KeyBy 해서 CCTV 로 부터 입력된 계산된 사람 숫자 평균값을 구하게 됩니다. (aggregate() 함수를 사용하여 각 윈도우 내에서 평균을 계산)
계산된 값은 spaceId 별로 Sink 하게 됩니다.
CCTV Event Server
1 |
|
여기서는 CCTV 로 부터 현재 실시간으로 촬영된 사람 카운트 숫자는 임의로 랜덤값을 지정 해서 설정 하도록 하겠습니다. 랜덤값으로 사람 카운트를 만들어서 랜덤으로 spaceId 값을 추출해
지정된 Kafka 에 데이터를 전송 하도록 구현 해보았습니다.
KafkaSource 설정 하기
1 | String inputTopic = params.get("input-topic", "input"); |
CCTV 로 부터 가져온 데이터를 Kafka 로 적재된 부분을 KafkaSource 이용해서 Consume 하는 과정 입니다. 우선 해당 Kafka 로 부터 데이터를 읽어오기 위해 Kafka 주소와 Topic 을 설정 하였습니다.
그런 다음 KafkaSource 를 만들게 됩니다. 어떤 토픽에서 가져 올 것인지 그리고 Deserializer 설정 해야 하는데 SpaceCongestionEventDeserializationSchema 객체 통해 어떻게 Deserialization 할 것인지 정의 합니다.
Offset 설정이 있는데 OffsetsInitializer.earliest() 방식으로 Offset 설정 한다고 정의 내렸습니다.
WatermarkStrategy 설정 하기
1 | WatermarkStrategy<SpaceCongestionEvent> watermarkStrategy = WatermarkStrategy |
그 다음은 WatermarkStrategy 설정 하는 구간 입니다. Flink 에서 지원하는 시간 전략을 두가지 종류로 선택 할 수 있는데
- Processing Time
- Event Time
있습니다. 여기서는 Event Time 형식으로 전략을 선택 하도록 하겠습니다. 그러기 위해서는 Event Time 이 발생한 데이터가 어떤 것인지 지정 해야 하는데요, SpaceCongestionEvent 객체서 timestamp 프로퍼티로 지정 하겠습니다.
1 | WatermarkStrategy |
그 다음은 Built-in Watermark Generator 설정 하는 방법 입니다. Watermark 생성을 forBoundedOutOfOrderness 방식으로 설정 하겠다는 건데요.
현재까지 들어온 이벤트 중에 (설정 한 Window 구역 마다) 가장 큰 timestamp 하고 지정한 특정 시간 (Duration.ofMillis(200)) 하고 빼서 Watermark Generator 합니다.
즉 각각의 데이터 이벤트가 환경에 따라 늦게 들어 올 수가 있는데 최대 200 millis 정도 늦게 도착 한다고 가정한다는 의미 입니다.
Window 설정 하기
1 | DataStream<SpaceCongestionEvent> clicks = env.fromSource(source, watermarkStrategy, "SpaceCongestionEvent Source"); |
그 다음은 Window 설정 하는 방법 입니다. 크게 flink 에서 window 설정 하는 방법은 3가지 있습니다.
Tumbling Window
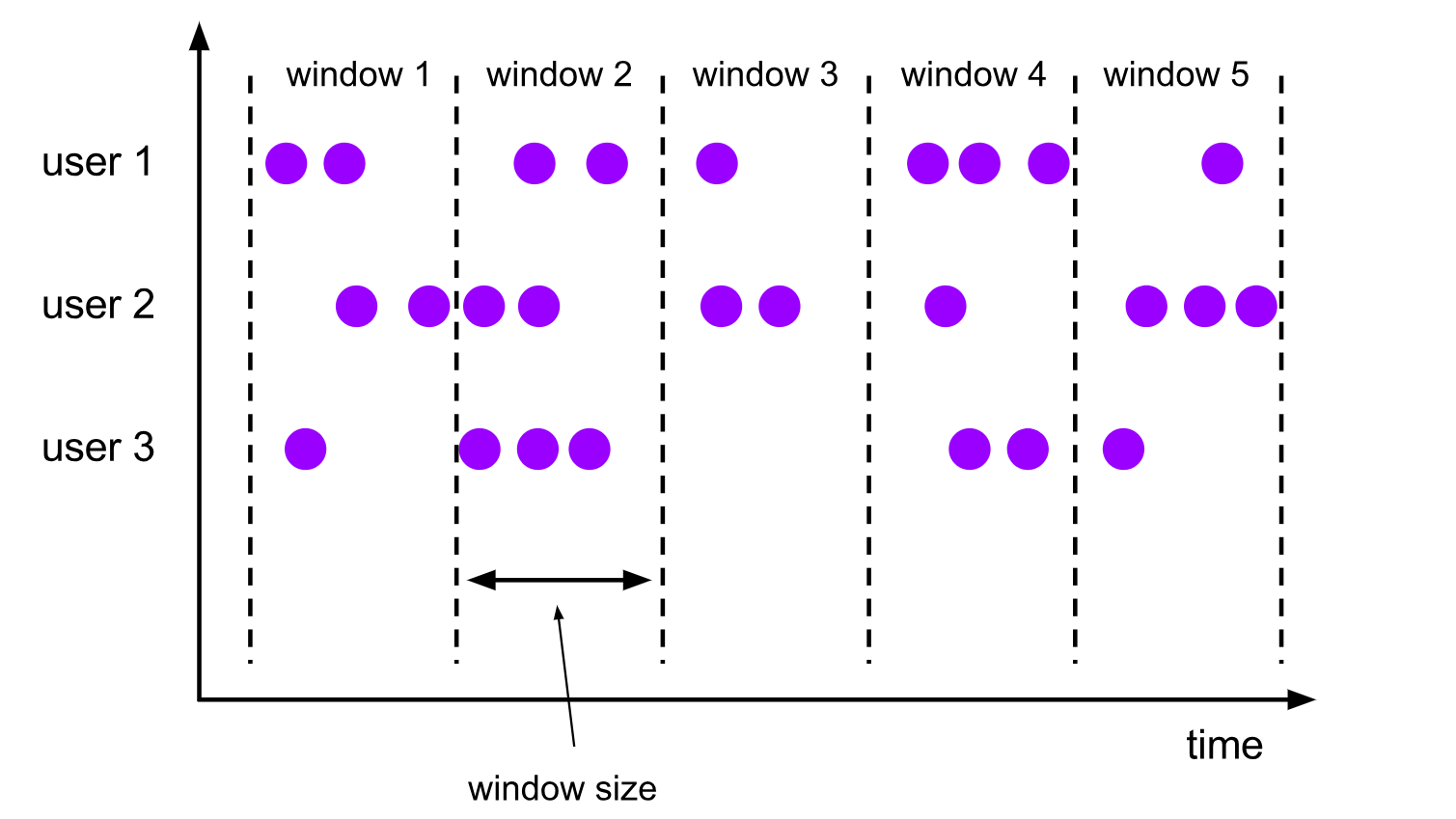
시간의 단위 기준 (window size) 으로 들어오는 모든 데이터들을 단순하게 자르는 방식 입니다.Sliding Window
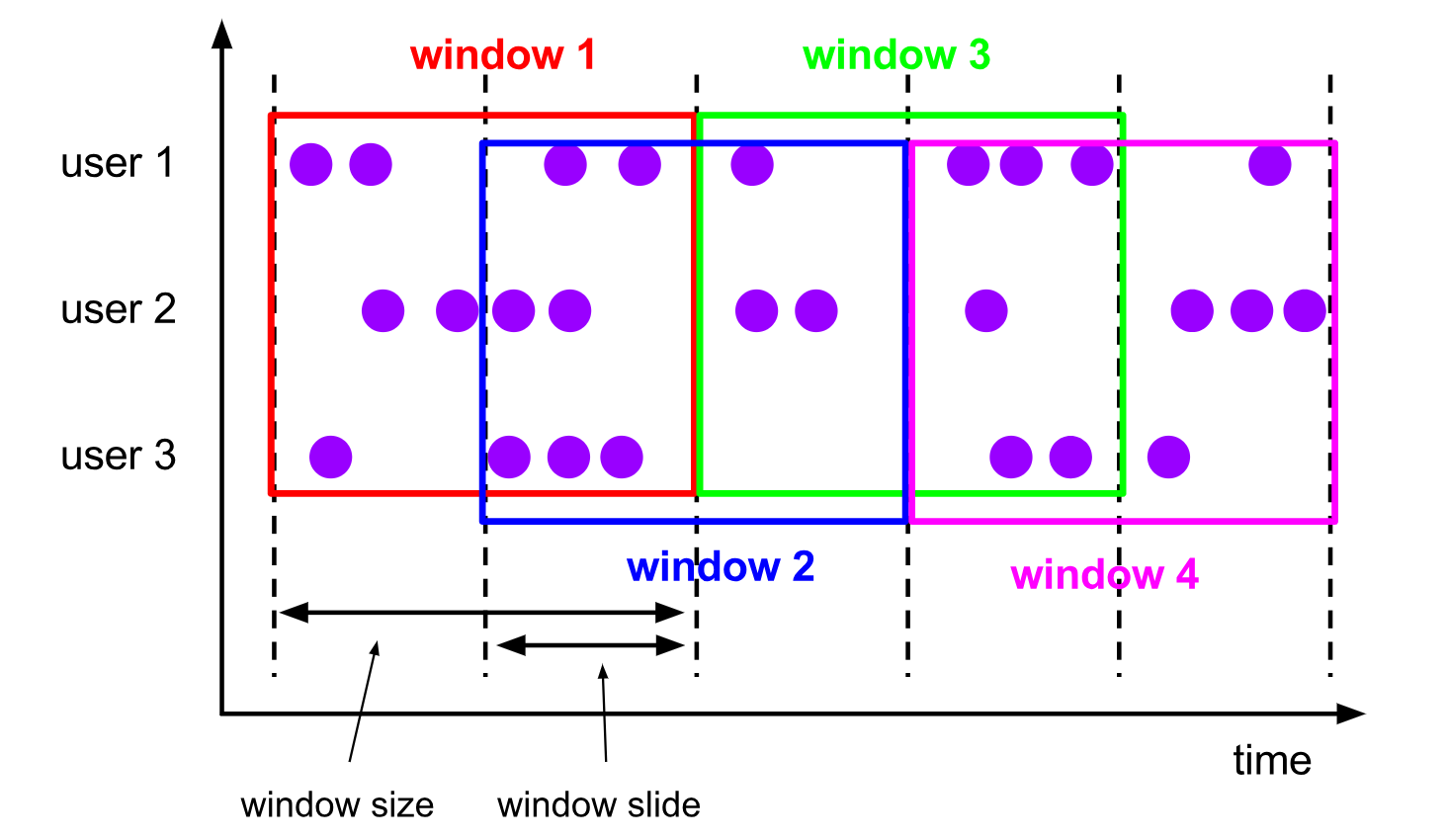
시간 단위 기준으로 (window size) 으로 들어와서 모든 데이터들을 단순하게 자르고 처리 하는 방식은 같은데
윈도우가 오버랩팅 되면서 지정한 window slide 기준으로 미끄러듯이 움직이면서 시간 단위 구역을 지정 한다고 생각 하시면 됩니다.Session Window
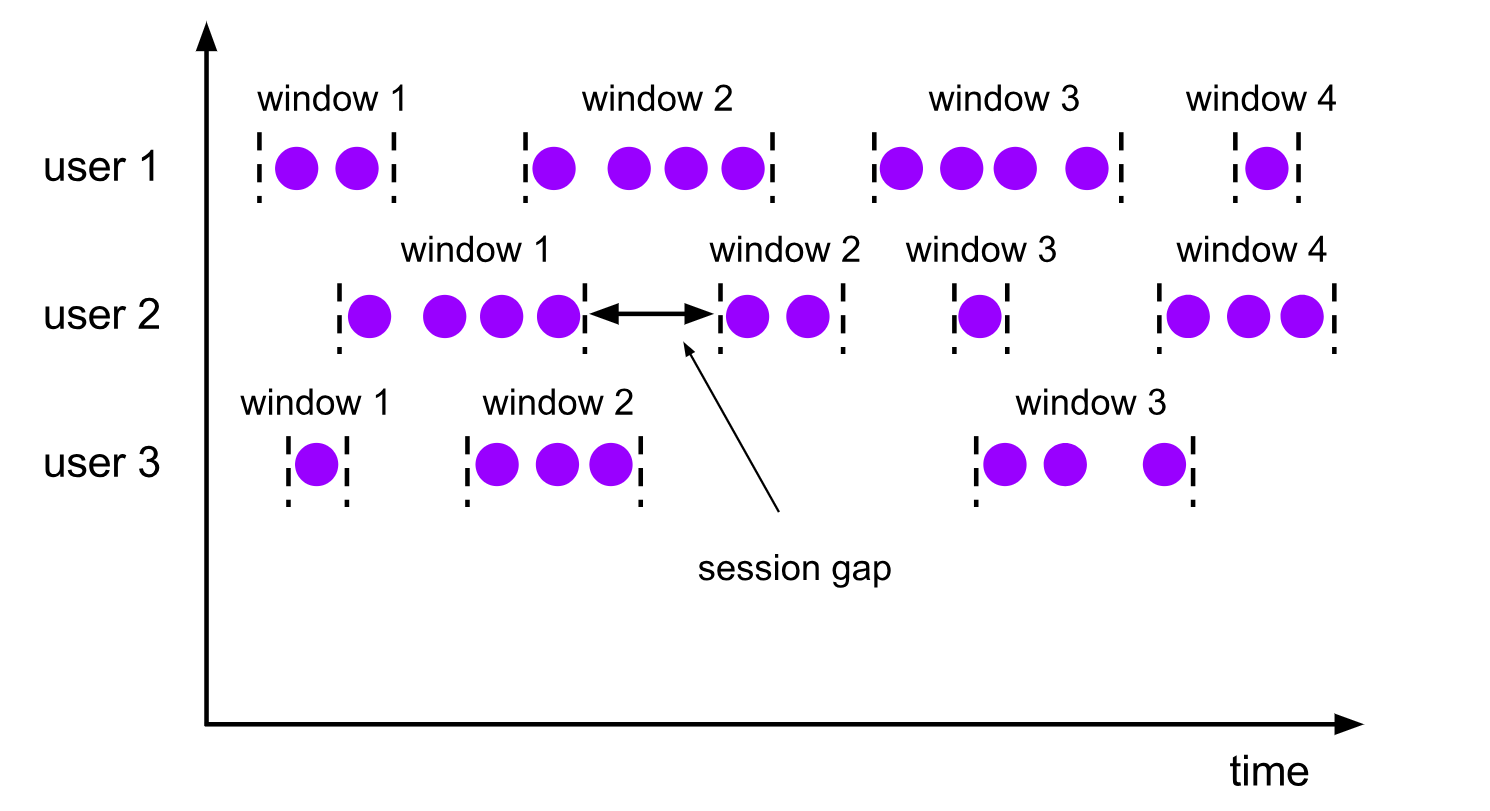
window 설정시 시작하는 단위하고 끝 단위를 지정하는 것이 아니라 데이터가 계속 들어오다가 특정 시간동안만 데이터가 들어오지 않으면 window 단위를 자르고
새로운 window 단위로 설정해서 각각의 구역을 지정 하겠다는 의미 입니다.
여기서는 flink 프로세스 띄울때 파라미터 값을 --event-time 이 지정되어 있으면 Tumbling Event Time Window 방식으로 처리 하고 해당 파라미터 값이 존재하지 않으면 Tumbling Processing Time Window 방식으로 처리 하도록 했습니다.
1 | .keyBy(SpaceCongestionEvent::getSpaceId) |
각각의 window 구역마다 keyBy 를 spaceId 값 기준으로 그룹핑 해서 처리 하도록 하겠다는 의미 입니다.
1 | .aggregate( |
다음은 aggregate 설정 하는 방법인데 SpaceCongestionAverageAggregator 객체를 확인 해보면 실시간으로 처리 되는 각각의 윈도우 구역에 요청 받은 PeopleCount 값들 중 평균값을 처리 하도록 설정 하였습니다.
그런 다음 SpaceCongestionEventStatisticsCollector 객체를 확인 해보면 SpaceCongestionEventStatistics 객체로 변환 시켜서 내보내겠다는 설정 방식 입니다.
Mysql Sink 설정 하기
1 | statistics.addSink( |
마지막으로 각각의 window 구역마다 분석 처리된 데이터를 Mysql 디비에 저장 하는 과정 입니다.
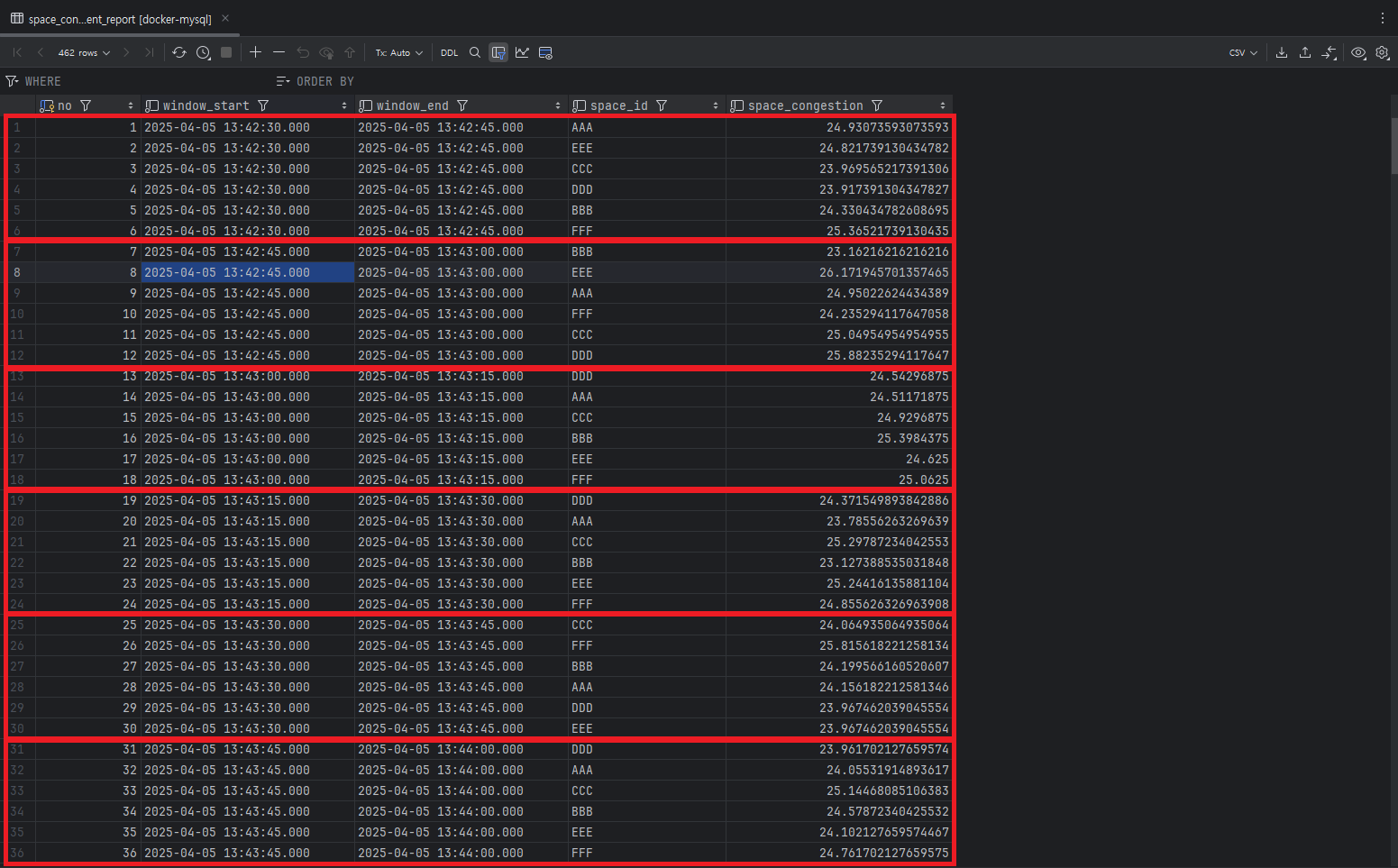
space_congestion 스키마에서 space_congestion_event_report 테이블을 확인 합니다.
Copyright 201- syh8088. 무단 전재 및 재배포 금지. 출처 표기 시 인용 가능.

