Index Dive 최적화
여러 MySQL 성능 최적화 방법 중 하나인 Index Dive 최적화에 알아볼려고 합니다.
‘Index Dive’ 는 Mysql 에서 실행 계획을 수립시 설정한 인덱스를 평가 하는 과정 입니다. 이러한 과정을 역활 하는 곳은 Mysql 옵티마이저 인데요.
옵티마이저는 실제 테이블의 데이터를 샘플링(조금씩 가져온다) 해서 검색에 사용할 데이터를 기반으로 실행 계획을 선택하게 됩니다.
하지만 이때 실제 데이터를 샘플링해서 확인하는 과정에서 잘못된 인덱스 설정 또는 비효율적으로 작성된 쿼리로 MySQL 옵티마이저가 실행 계획 수립시 많은 시간이 소요하게 됩니다.
SQL 최적화
앞써 이야기한 ‘Index Dive’ 대해 알아보았는데 옵티마이저가 ‘SQL 최적화’ 에 대해 전체적인 과정을 알아보겠습니다.
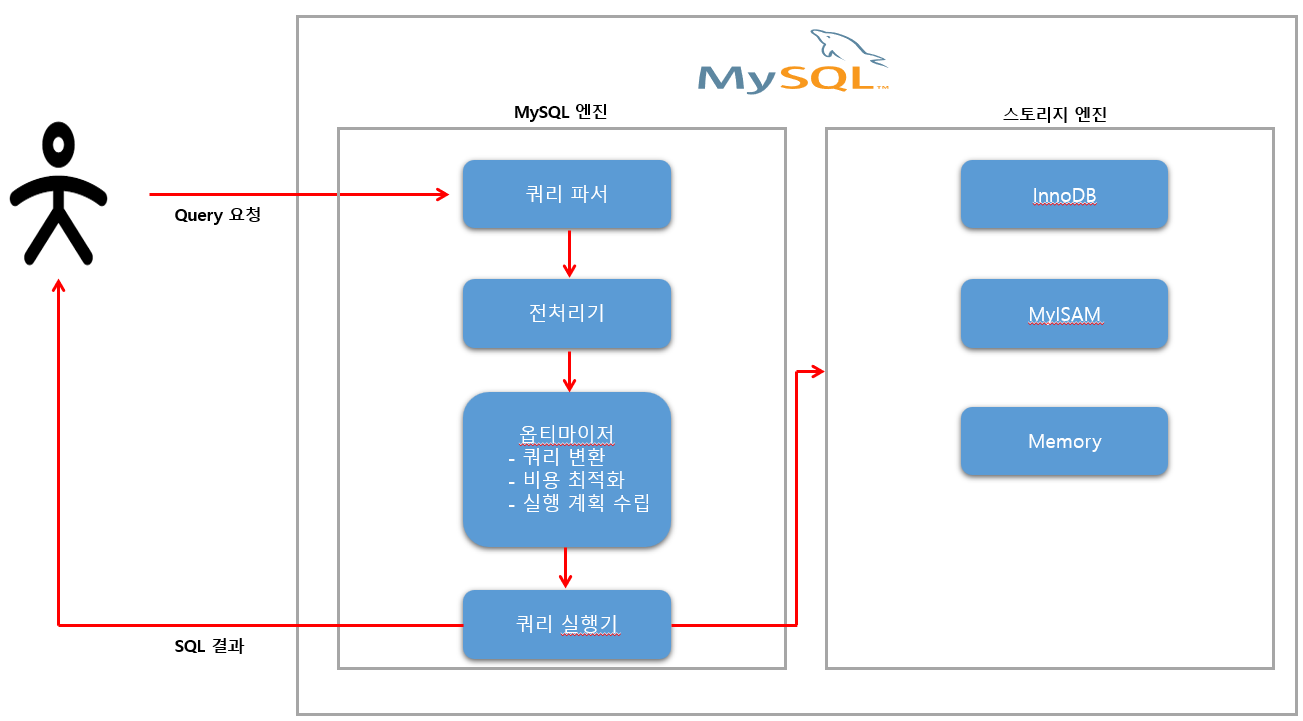
- 쿼리 파서
먼저 SQL 요청이 들어오면 Mysql 엔진 내에서 ‘쿼리 파서’ 발생 합니다. 요청이 들어온 쿼리 문장을 토큰으로 분리해 트리 형태 구조로 만들어 내는 작업 입니다.
- 전처리기
트리 형태로 구조로 만든 형태를 쿼리 문장에 문제점이 있는지 체크 하게 됩니다.
- 옵티마이저
쿼리 문장을 효율적인 최저 비용으로 어떻게 가장 빠르게 처리 할지를 결정하는 역활을 합니다. 여기서 실행 계획 수립시 가장 큰 우선순위가 바로 Index Dive 를 이용한 최적의 인덱스를 조사 하게 됩니다.
- Index Dive 를 이용한 예측
- 히스토그램을 이용한 에측
- 인덱스 통계를 이용한 에측
이번에 우리가 알아보는 것은 Index Dive 를 이용한 예측하는 과정에서 비효율적으로 작성된 쿼리로 인해 많은 시간을 소요로 어떻게 하면 최적화 할 수 있는지 입니다.
Index Dive 비용이 많이 발생되는 CASE:
1 | SELECT |
해당 쿼리문을 보시면 IN() 절에 많은 데이터가 있는 경우 입니다. 예시로 member_id 에 “1” 이라는 값을 통해 Index Dive 이용해서 적절한 인덱스를 판단 합니다.
member_id = “1” 이라는 조건에 첫번째 Index Dive 이 발생되고 이때 인덱스의 시작 부분을 탐색합니다.
그 다음 두번째 Index Dive 발생하는데요. member_id = “1” 에 대한 인덱스 마지막 부분을 탐색 합니다. 이렇게 하나의 where 조건에 두번의 Index Dive 실행 합니다.
IN 절에 한 두개만 정도 존재하면 문제는 없겠지만 이렇게 1000 개 IN 절이 포함 되어 있다면 큰 리소스 발생으로 이어지게 됩니다.
MySQL 경우는 아래와 같은 케이스 경우 Index dive 발생 하지 않습니다.
- 하나의 테이블에만 접근하는 쿼리의 경우
- FORCE INDEX 가 단일 인덱스에 적용 될 경우
- 서브쿼리가 없는 경우
- Fulltext 인덱스가 관련되지 않을 경우 * Fulltext 인덱스는, 긴 텍스트 데이터를 위한 MySQL에서 제공하는 인덱스이다.
- GROUP BY나 DISTINCT 절이 없을 경우
- ORDER BY 절이 없을 경우
이번 실습 경우는 FORCE INDEX 이용해서 비효율적인 Index dive 발생 하지 않도록 해볼려고 합니다.
실습 통해 알아보자
1 | create table members |
1 | CREATE INDEX idx_member_id ON members(member_id, created_date); |
idx_member_id 이라는 인덱스를 생성 하도록 합니다.
TEST 대상이 되는 테이블인 members 이라는 테이블을 생성 하도록 합니다.
1 | SHOW VARIABLES LIKE 'performance_schema'; |
그런 다음 Index Dive 확인 하기 위해서는 performance_schema 가 활상화 되어져야 합니다.
1 | UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES' WHERE NAME LIKE 'statement/%'; |
퍼포먼스 스키마에 필요한 지표들을 수집 하도록 하고 테이블에 저장 할 수 있도록 합니다.
1 | SHOW SESSION VARIABLES LIKE 'eq_range_index_dive_limit'; |
다음으로 Index Dive 를 제어 하는 변수 eq_range_index_dive_limit 변수 값 확인 합니다.
디폴트 값은 200 입니다. Index Dive 실행시 이 값보다 동등 조건 많이 발생하게 된다면 Index Dive 는 취소가 됩니다. 그런 다음 히스토그램 아니면인덱스 통계 를 통해 인덱스 에측 및 결정 하게 됩니다.
1 | TRUNCATE TABLE performance_schema.events_statements_history_long; |
기존에 수집된 성능 지표를 모두 제거 합니다.
1 | SELECT * |
해당 쿼리를 실행 합니다. 비효율적인 Index dive 실행해서 지연 하도록 합니다.
1 | SELECT * |
이번에는 최적화를 합니다. 즉 idx_member_id 인덱스를 FORCE INDEX 통해 강제로 인덱스 설정을 하고 Index dive 실행하지 않도록 해서 쿼리를 실행 합니다.
1 | SELECT stages.EVENT_ID, statements.EVENT_ID, statements.END_EVENT_ID, statements.SQL_TEXT, stages.EVENT_NAME, stages.TIMER_WAIT / 100 |
performance_schema 를 통해 성능 비교 해봅니다.
Copyright 201- syh8088. 무단 전재 및 재배포 금지. 출처 표기 시 인용 가능.

