Spring Batch - Chunk
Spring Batch 에서 Chunk 대해 알아보겠습니다.
여기서 말하는 Chunk 라는 의미는 대용량 데이터를 정해진 Chunk 단위로 묶어서 처리 한다는 의미를 갖고 있습니다.
예를들어 100개 데이터가 존재하고 Chunk 단위는 10개라고 가정한다면 100개 데이터를 10개로 묶어 10번 처리를 한다고 보시면 되겠습니다. 동시에 Transaction 처리도 하게 됩니다.
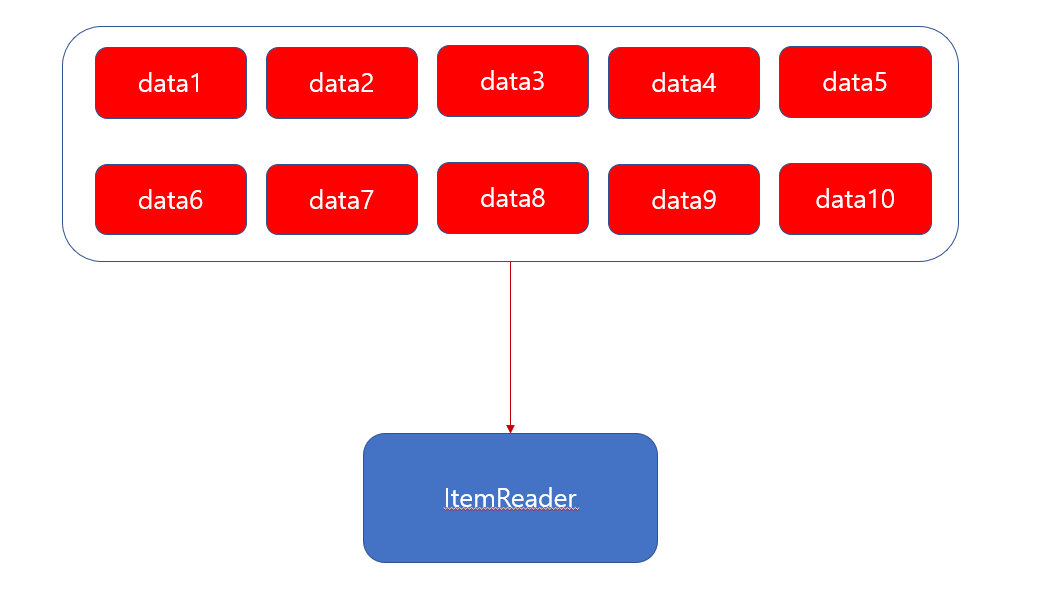
Arrays.asList("data1", "data2", "data3", "data4", "data5", "data6", "data7", "data8", "data9", "data10"
Array 에 String 형식으로 총 10개 데이터가 있다고 가정 하겠습니다. 그리고 Chunk Size 는 2개 입니다.
ItemReader 는 여기서 Chunk Size 는 2개 만큼 가져오게 됩니다. 즉 반복해서 하나하나씩 Chunk Size 만큼 데이터를 가져 오게 됩니다.
즉 “data1”, “data2” 데이터를 추출 하게 됩니다.
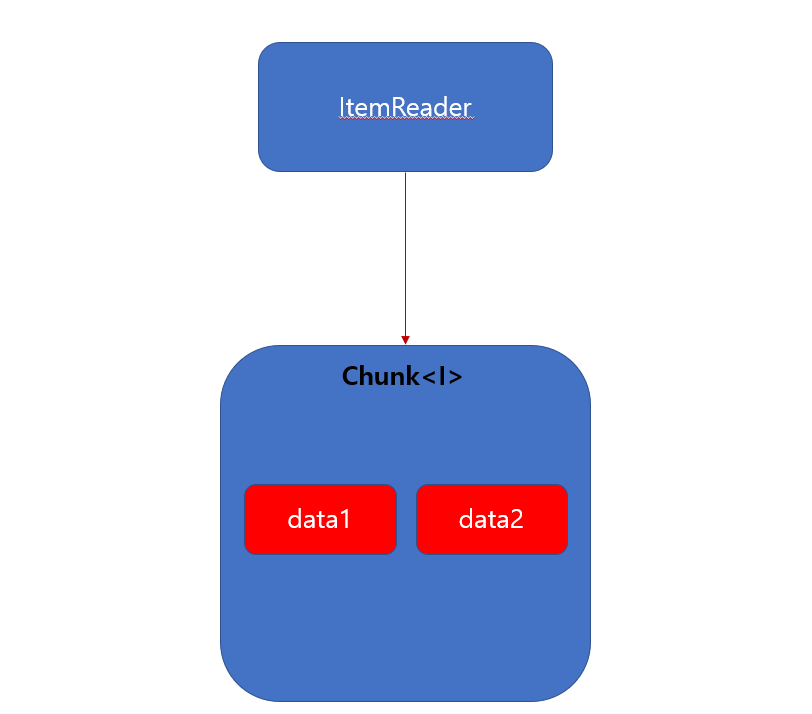
“data1”, “data2” 이 두개 데이터를 Chunk 데이터로 채우게 됩니다. Chunk 객체는 ItemProcessor 로 가게 됩니다.
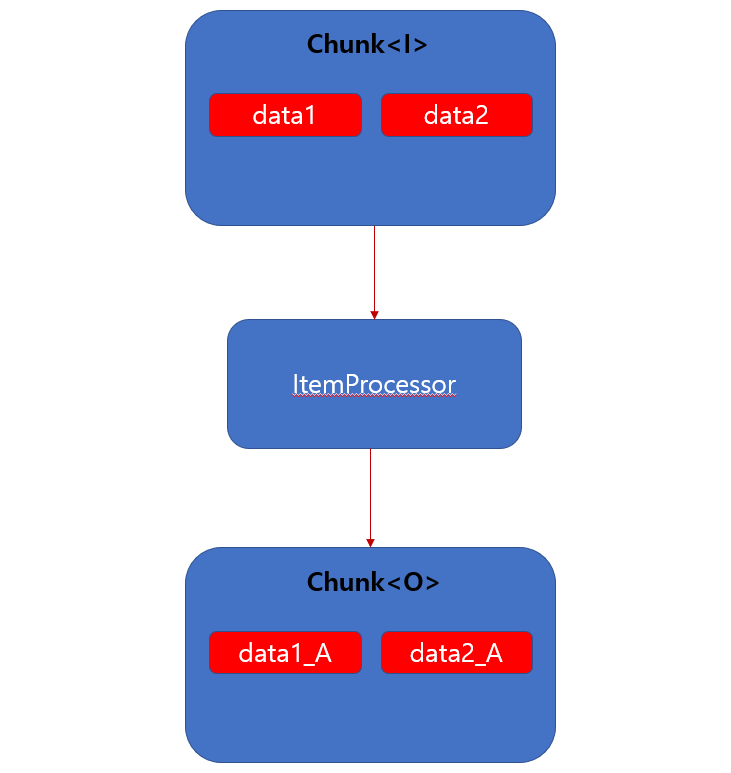
Chunk 객체는 List 형식이기 때문에 반복해서 각각의 데이터를 {데이터}_A 로 변환 시키게 됩니다. 변환한 하나하나 데이터는 Chunk
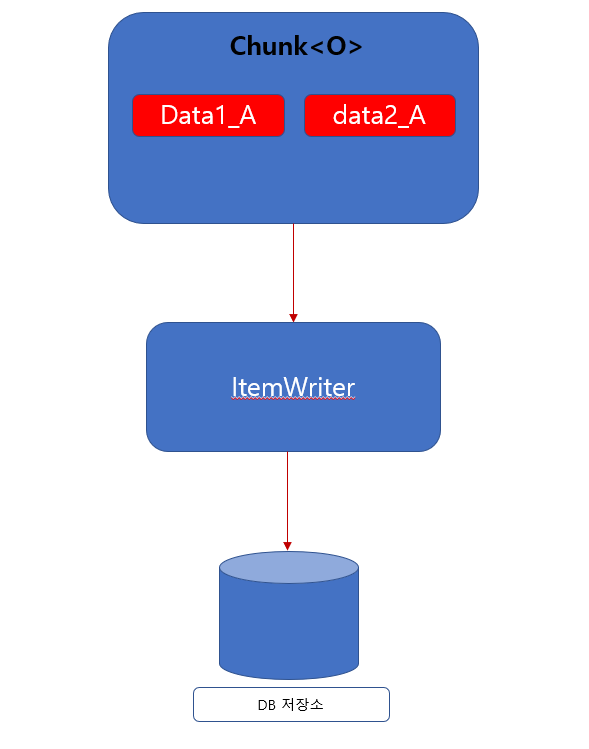
Chunk
이렇게 처리가 끝나면 다시 Chunk Size 대로 반복 과정이 일어나게 됩니다.
즉 총 10개 데이터가 있고 Chunk Size 는 2 입니다. 그럼 총 5번 반복 하게 됩니다.
실습 해보자
1 | @RequiredArgsConstructor |
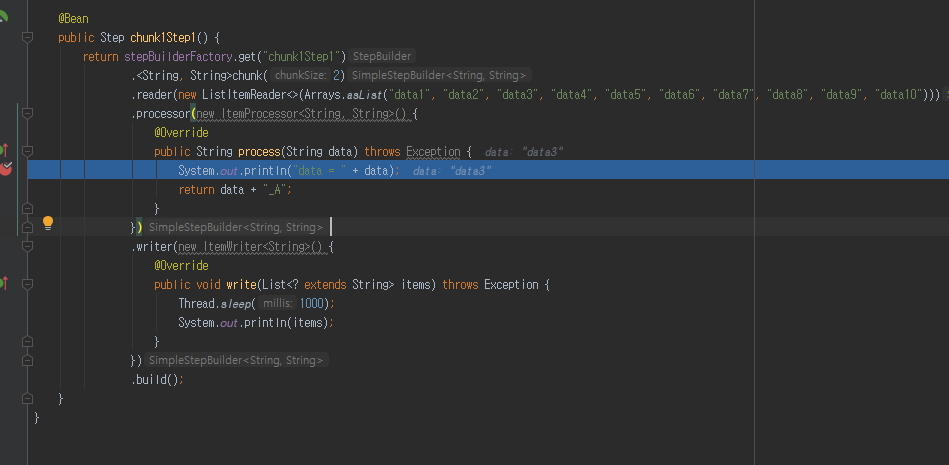
‘chunk1Job1’ Job 이 실행하면 ‘chunk1Step1’ Step 이 실행 됩니다.
여기서 데이터는
Arrays.asList("data1", "data2", "data3", "data4", "data5", "data6", "data7", "data8", "data9", "data10")
로 구성 해보았습니다.
ItemReader 에서 <String, String>chunk(2) chunk 사이즈를 2로 설정했기 때문에 10 개 데이터 중 2개만 추출해서 ItemProcessor 로 전달하게 됩니다.
이후 가공한 데이터를 ItemWriter 가 처리 하게 됩니다.
<String, String> 첫번째 타입은 String 으로 되어 있는데 ItemReader 통해 얻은 데이터 타입이고 두번째 타입도 String 인데 write 에 요청 받을시 데이터 타입 입니다.
Chunk 자세히 알아보자
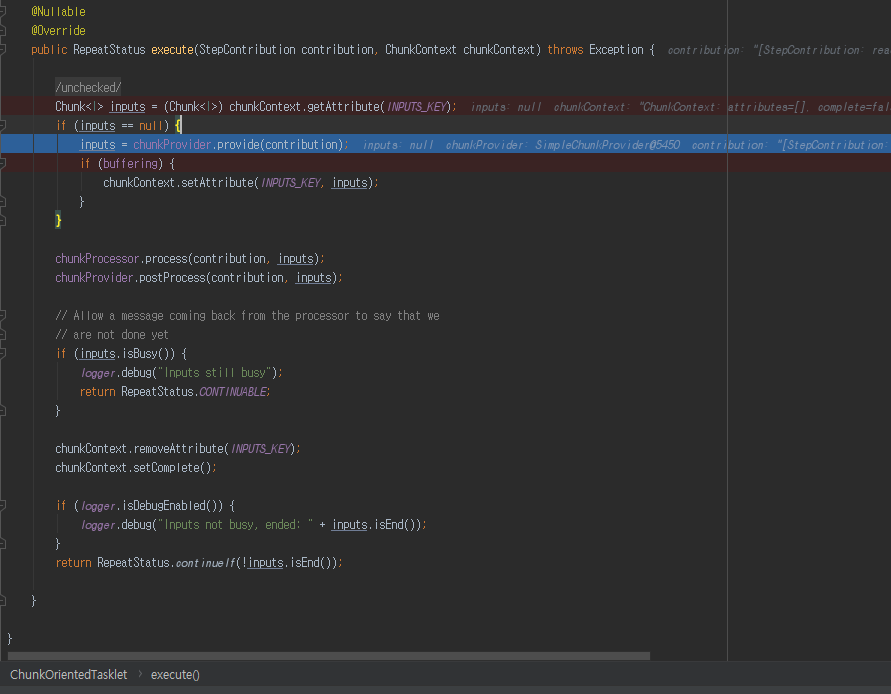
ChunkOrientedTasklet 클래스는 Tasklet 인터페이스 구현체 입니다. 또한 chunk 지향 프로세싱을 담당하는 객체라고 보시면 되겠습니다.
execute 메소드를 실행하게 된다면
Chunk<I> inputs = (Chunk<I>) chunkContext.getAttribute(INPUTS_KEY);
chunkContext 에서는 아직 저장 한적이 없기 때문에 null 로 반환하게 됩니다.
하지만 Chunk 실행 도중 예외가 발생되고 다시 실행 하게 된다면 다시 데이터를 읽지 않고
chunkContext 에 저장했던 데이터를 가져와서 실행하게 됩니다.
chunkProvider.provide(contribution);
실행하게 됩니다.
chunkProvider 는 chunk 단위 아이템을 제공하는 클래스 입니다.
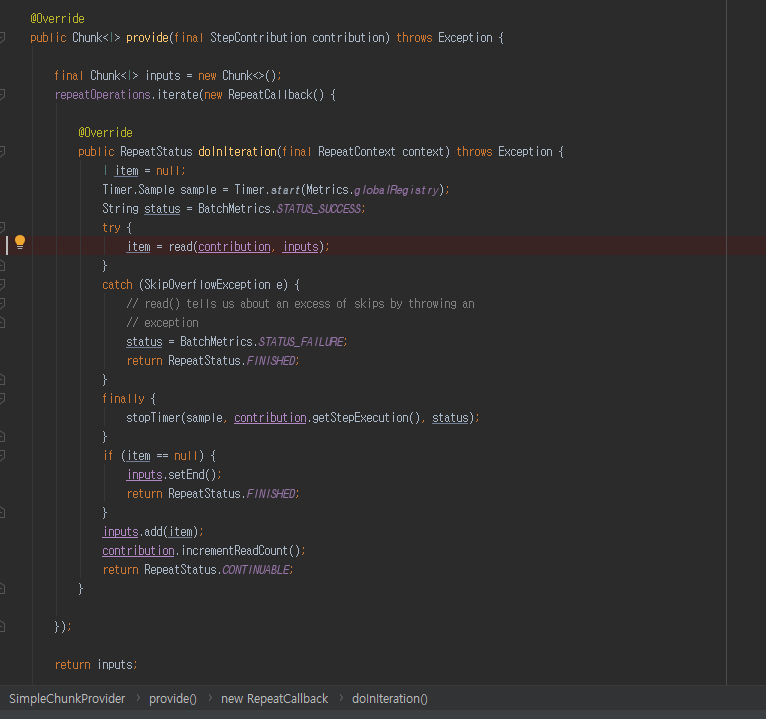
여기서 final Chunk<I> inputs = new Chunk<>(); Chunk 를 생성하게 됩니다.
item = read(contribution, inputs);
우리가 설정 item 10개 중 하나의 데이터를 read 메소드 통해 가져오고 있습니다.
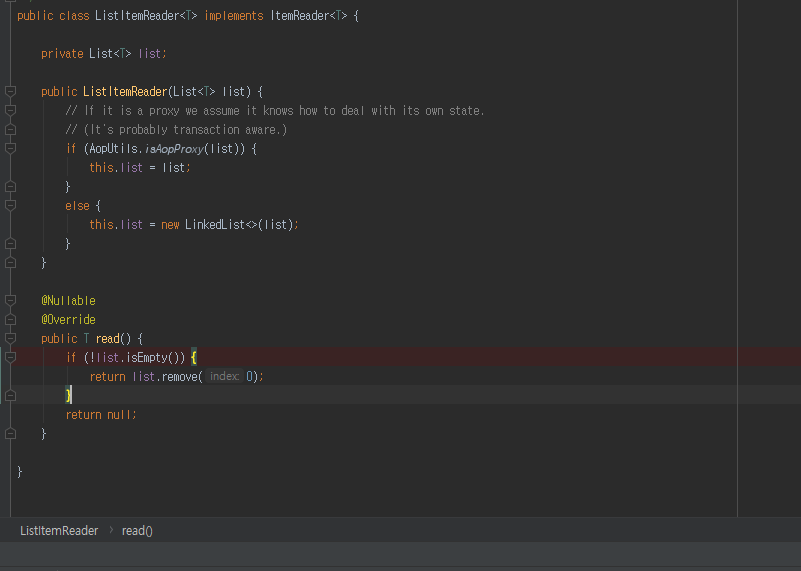
return list.remove(0);
list 변수에는 우리가 설정한 10 개 데이터가 있습니다. 그중에 remove 메소드를 실행해서 하나의 데이터를 빼오겠다는 의미입니다.
우리가 chunk size 를 2로 설정했습니다. 이 process 를 총 2번 반복 하게 됩니다.
chunkProcessor.process(contribution, inputs);
chunk size 대로 가져온 2개 데이터는 itemProcessor 로 전달하기 위해 해당 메소드를 실행하게 됩니다.
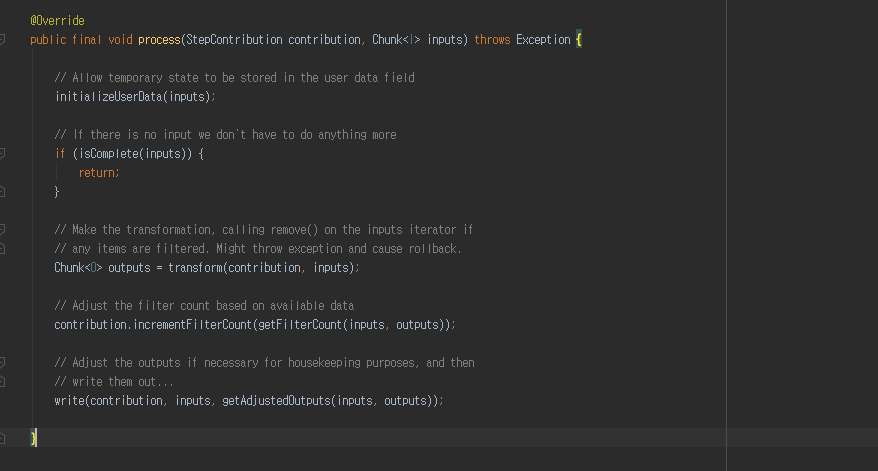
Chunk<O> outputs = transform(contribution, inputs);
transform 메소드를 실행해 생성한 Chunk
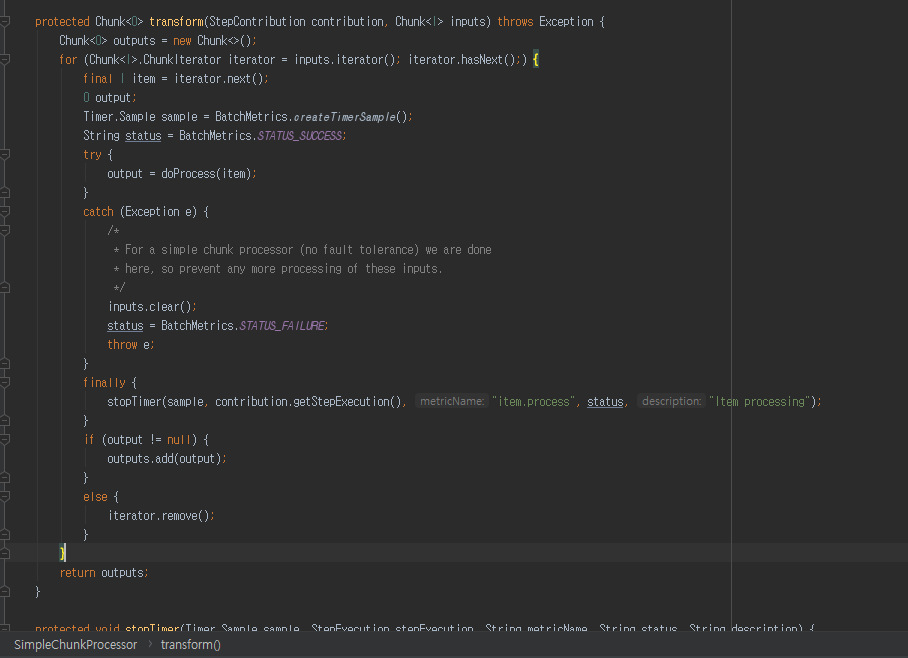
Chunk<O> outputs = new Chunk<>(); 반환 Chunk
for (Chunk<I>.ChunkIterator iterator = inputs.iterator(); iterator.hasNext();) {
그전에 Chunk 를 만들었던 객체를 for 문 통해 로직이 실행 됩니다.
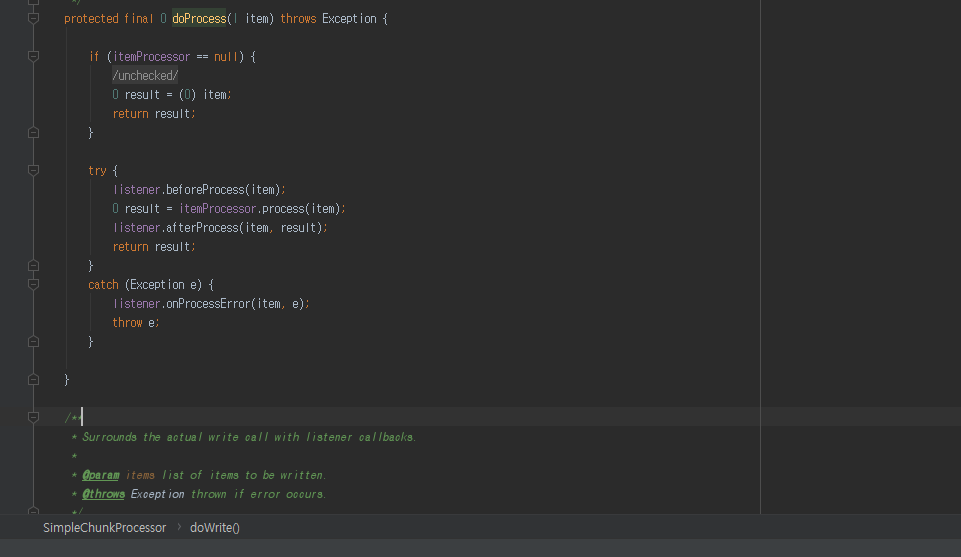
하나의 item 를 추출해서 doProcess 메소드를 실행 하게 됩니다.
우리가 Job 을 설정한 BasicChunkConfiguration 클래스의 정의한 process 메소드로 가서 해당 데이터를 가공 하게 됩니다.
이 로직은 chunk size 를 2로 설정했으니 2번 반복해서 Chunk
SimpleChunkProcessor 클래스에서 process 메소드 통해 반환 받은 Chunk
write(contribution, inputs, getAdjustedOutputs(inputs, outputs));
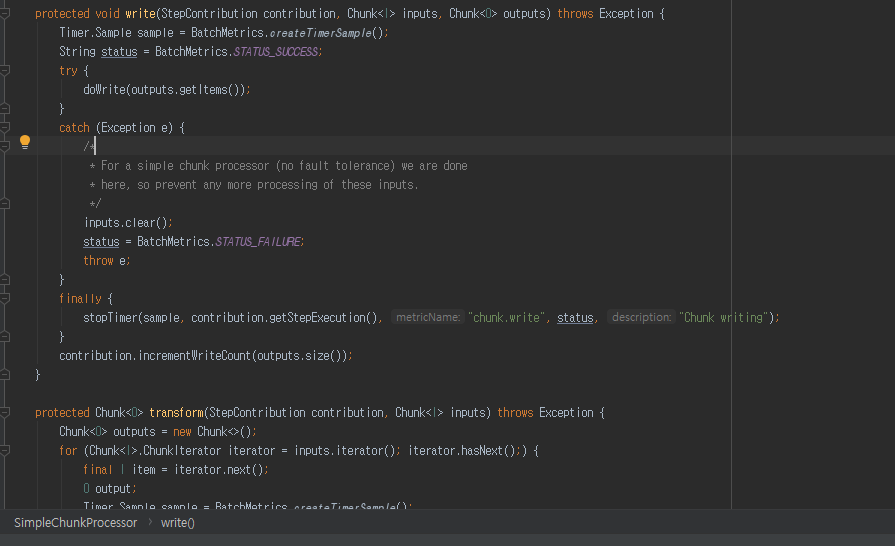
doWrite(outputs.getItems());
메소드를 실행 하게 된다면
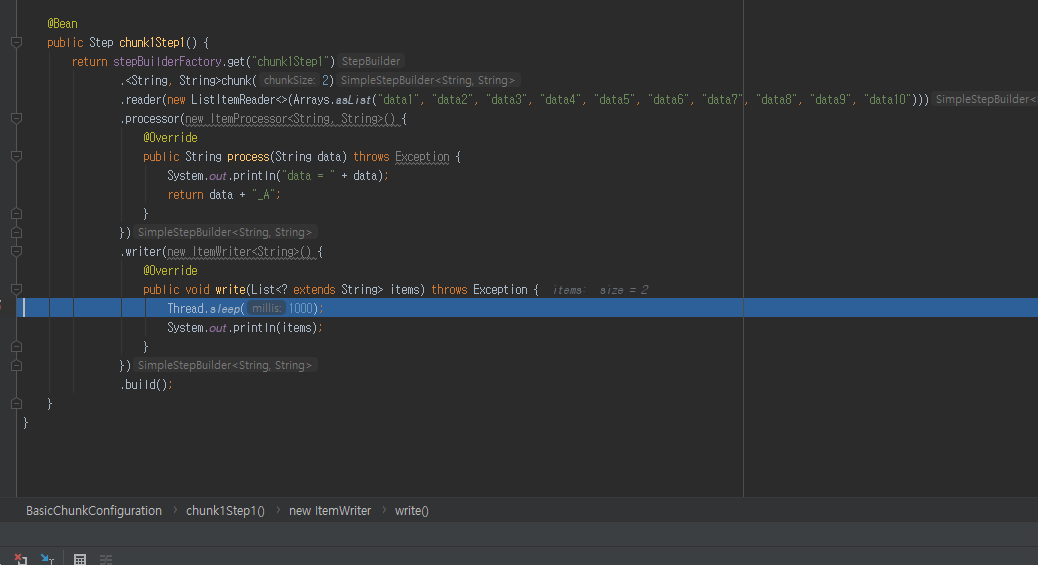
우리가 Job 을 설정한 BasicChunkConfiguration 클래스의 정의한 wirte 메소드로 가서 해당 데이터를 쓰기 작업을 하게 됩니다.
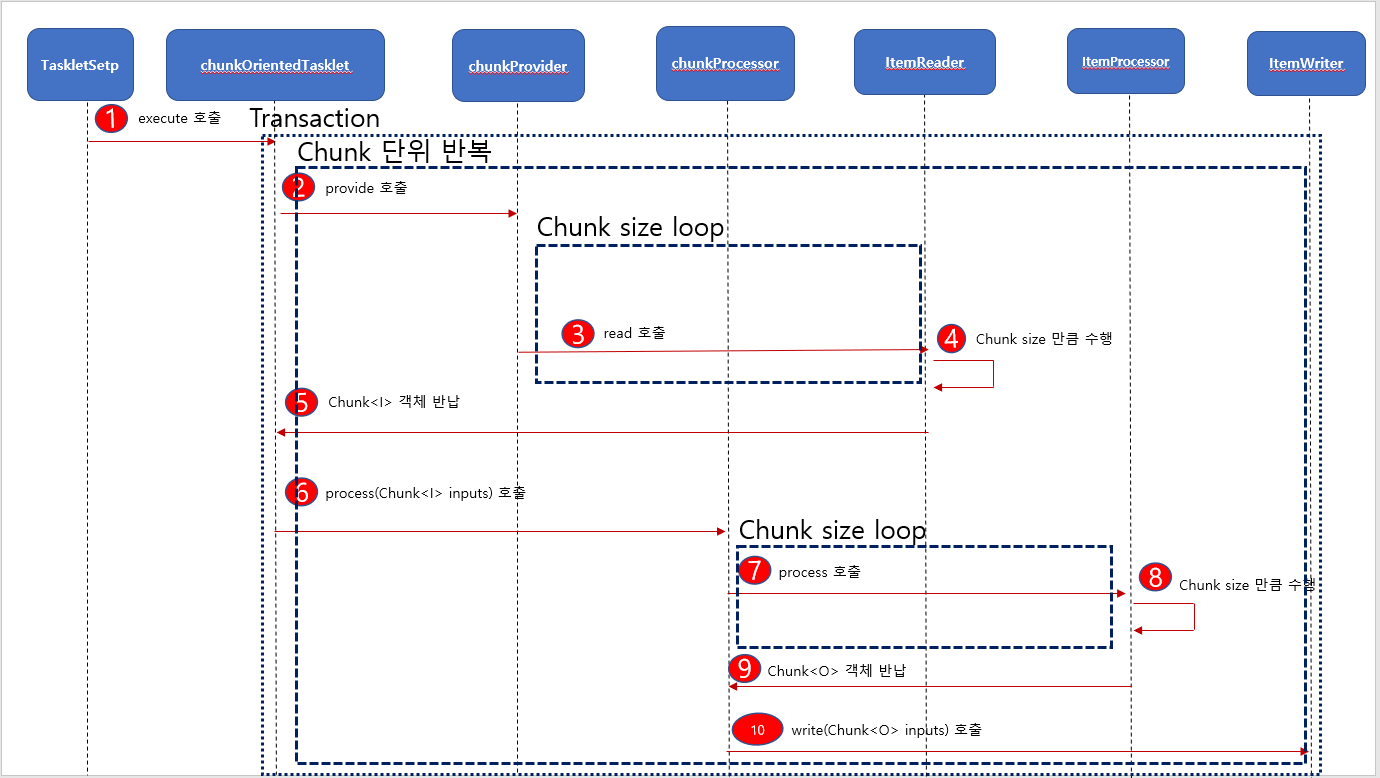
다이어그램 통해 해당 내용을 정리 한것 입니다.
Copyright 201- syh8088. 무단 전재 및 재배포 금지. 출처 표기 시 인용 가능.

