동기화 기법
뮤텍스(Mutual Exclusion)
• 뮤텍스(Mutual Exclusion) 또는 상호 배제는 공유 자원에 대한 경쟁 상태를 방지하고 동시성 제어를 위한 락 메커니즘이다
• 스레드가 임계영역에서 Mutex 객체의 플래그를 소유하고 있으면(락 획득) 다른 스레드가 액세스할 수 없으며 해당 임계영역에 액세스하려고 시도하는 모든 스레드는 차단되고
Mutex 객체 플래그가 해제된 경우(락 해제)에만 액세스할 수 있다
• 이 메커니즘은 Mutex 락을 가진 오직 한개의 스레드만이 임계영역에 진입할 수 있으며 락을 획득한 스레드만이 락을 해제 할 수 있다
✔ 뮤텍스 문제점
• 데드락(Deadlock)
데드락은 두 개 이상의 스레드가 서로가 가진 략을 기다리면서 상호적으로 블로킹되어 아무 작업도 수행할 수 없는 상태를 의미하며 잘못된 뮤텍스 사용으로 인해
데드락이 발생할 수 있다.
• 우선 순위 역전(Priority Inversion)
우선 순위 역전은 높은 우선 순위를 가진 스레드가 낮은 우선 순위를 가진 스레드가 보유한 락을 기다리는 동안 블록되는 현상으로 높은 우선 순위를 가진 스레드의
작업이 지연될 수 있다. 우선 순위 상속으로 해결할 수 있다
• 오버헤드
뮤텍스를 사용하면 여러 스레드가 경합하면서 락을 얻기 위해 스레드 스케줄링이 발생한다. 이로 인해 오버헤드가 발생하고 성능이 저하될 수 있다
• 성능 저하
뮤텍스를 사용하면 락을 얻기 위해 스레드가 대기하게 되고, 스레드의 실행 시간이 블록되면서 성능 저하가 발생할 수 있다
• 잘못된 사용
뮤텍스를 적절하게 사용하지 않거나 잘못된 순서로 락을 해제하는 경우 예기치 않은 동작이 발생할 수 있다
세마포어
• 세마포어는 공유 자원에 대한 접근을 제어하기 위해 사용되는 신호전달 메커니즘 동기화 도구이다
• 세마포어는 정수형 변수 S와 P(Proberen: try), V(Verhogen: increment)의 두 가지 원자적 함수로 구성된 신호전달 메커니즘 동기화 도구이다
• P는 임계 영역을 사용하려는 스레드의 진입 여부를 결정하는 연산으로 Wait 연산이라고도 하고 V 는 대기 중인 프로세스를 깨우는 신호(Wake-up)로 Signal 연산이라고 한다
• 스레드가 임계영역에 진입하지 못할 경우 자발적으로 ‘대기(BLOCK)’상태에 들어가고 임계영역을 빠져나오는 스레드가 대기상태의 스레드를 실행대기상태로 깨워준다
• 자바에서는 java.util.concurrent 패키지에 세마포어 구현체를 포함하고 있기 때문에 직접 세마포어를 구현할 필요는 없다
LRU 캐시에 대해 설명하시오.
LRU 캐시는 Least Recently Used 캐시로 캐시 메모리가 다 차면, 가장 오랫동안 사용되지 않았던 캐시를 메모리에서 삭제하는 알고리즘입니다.
캐시를 교체하는 알고리즘이 어떤 것 들이 있는지 이해해두면 좋습니다.
- 캐시 교체 알고리즘의 종류 예시
- FIFO (first in first out)
페이지가 주기억장치에 적재된 시간을 기준으로 교체될 페이지를 선정하는 기법
단점 : 중요한 페이지가 오래 있었다는 이유만으로 교체되는 불합리. 가장 오래 있었던 페이지는 앞으로 계속 사용될 가능성이 있음.
- LFU (least frequently used)
가장 적은 횟수를 참조하는 페이지를 교체
단점 : 참조될 가능성이 많음에도 불구하고 횟수에 의한 방법이므로 최근에 사용된 프로그램을 교체시킬 가능성이 있고, 해당 횟수를 증가시키므로 오버헤드 발생
- LRU (least recently used)
가장 오랫동안 참조되지 않은 페이지를 교체
단점 : 프로세스가 주기억장치에 접근할 때마다 참조된 페이지에 대한 시간을 기록해야함. 큰 오버헤드가 발생
OAUTH 2.0 이해하기
https://syh8088.github.io/2021/11/27/AUTHTICATION/OAUTH/oauth/
cache 관련 질문
https://witty-toad-850.notion.site/8a0d4f02b3d8422f9133a460f09d8689
인덱스 면접 대비
https://witty-toad-850.notion.site/28e94cce4b2d4dcfaaf2eea77085c230
비동기 면접 대비
https://witty-toad-850.notion.site/4e935fc127e94a6b83dc99a5bcc27d7f
그외 면접 대비
https://witty-toad-850.notion.site/f2fd5039c39f4eb69dd4d674f9080bae
Kafka 와 Redis 의 Pub/Sub 비교
https://devoong2.tistory.com/entry/Kafka-%EC%99%80-Redis-%EC%9D%98-PubSub-%EB%B9%84%EA%B5%90
https://kadensungbincho.tistory.com/152
객체지향 5대 원칙
SRP: Single Responsibility Principle
✔ 하나의 클래스는 단 한 가지의 변경 이유만을 가져야 한다.
→ ‘변경 이유’ = 책임
✔ 객체가 가진 공개 메서드, 필드, 상수 등은 해당 객체의 단일 책임에 의해서만 변경 되는가?
✔ 관심사의 분리
✔ 높은 응집도, 낮은 결합도
OCP: Open-Closed Principle
✔ 확장에는 열려 있고, 수정에는 닫혀 있어야 한다.
→ 기존 코드의 변경 없이, 시스템의 기능을 확장할 수 있어야 한다.
✔ 추상화와 다형성을 활용해서 OCP를 지킬 수 있다.
LSP: Liskov Substitution Principle
✔ 상속 구조에서, 부모 클래스의 인스턴스를 자식 클래스의 인스턴스로 치환할 수 있어야 한다.
→ 자식 클래스는 부모 클래스의 책임을 준수하며, 부모 클래스의 행동을 변경하지 않아야 한다.
ISP: Interface Segregation Principle
✔ 클라이언트는 자신이 사용하지 않는 인터페이스에 의존하면 안 된다.
→ 인터페이스를 잘게 쪼개라!
✔ ISP를 위반하면, 불필요한 의존성으로 인해 결합도가 높아지고, 특정 기능의 변경이 여러 클래스에 영향을 미칠 수 있다.
DIP: Dependency Inversion Principle
✔ 상위 수준의 모듈은 하위 수준의 모듈에 의존해서는 안 된다. 둘 모두 추상화에 의존해야 한다.
✔ 의존성의 순방향 : 고수준 모듈이 저수준 모듈을 참조하는 것
의존성의 역방향 : 고수준, 저수준 모듈이 모두 추상화에 의존하는 것
→ 저수준 모듈이 변경되어도, 고수준 모듈에는 영향이 가지 않는다.
GC 가비지 컬렉션에 대해 아는 대로 설명하시오
GC 가비지 컬렉션은 프로그래머가 동적으로 할당한 메모리 영역 중 더 이상 쓰이지 않는 가비지 영역을 찾아서 해제하는 기능을 의미합니다. 답변 시 Full GC에 대해서도 설명할 수 있으면 좋습니다.
자바 메모리는 Young, Old, Perm 세 영역으로 나뉩니다. 이 중 Perm(Permanent) 영역은 거의 사용되지 않으며
Yong(Eden, Survivor), Old 2가지 영역으로 나뉘어있습니다.
객체는 처음 생성되었을 때 Yong 영역에 있다가 Old 영역으로 넘어가게 되는데,
Old 영역이 꽉 찼을 때 Full GC 가 발생하게 됩니다. Full GC가 발생하면 애플리케이션에 부하가 발생하여 성능이
Full GC 발생 순간에 저하됩니다. 자바 성능상 이슈를 유발할 수 있는 Full GC의 이론에 대해 알아두면 좋습니다.
☕-가비지-컬렉션GC-동작-원리-알고리즘
Multiple-Column Indexes For Optimization
Covering Index For Optimization
https://algoalgo.notion.site/Covering-Index-For-Optimization-371cc1b5915141c5ba17aac1da9c6441
ORDER BY Optimization
https://algoalgo.notion.site/ORDER-BY-Optimization-8a454b5816bf4c10912191b1269d0033
index dive
https://medium.com/daangn/index-dive-%EB%B9%84%EC%9A%A9-%EC%B5%9C%EC%A0%81%ED%99%94-1a50478f7df8
https://nooblette.tistory.com/entry/MySQL-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EB%8B%A4%EC%9D%B4%EB%B8%8CIndex-Dive-%ED%98%84%EC%83%81%EA%B3%BC-%EB%B0%A9%EC%A7%80%ED%95%98%EA%B8%B0
https://velog.io/@fishphobiagg/%EC%B9%9C%EC%A0%88%ED%95%9C-SQL-%ED%8A%9C%EB%8B%9D-SQL-%EC%B2%98%EB%A6%AC%EA%B3%BC%EC%A0%95-%EB%B0%8F-IO-With-MySQL
Where절 조건의 유형
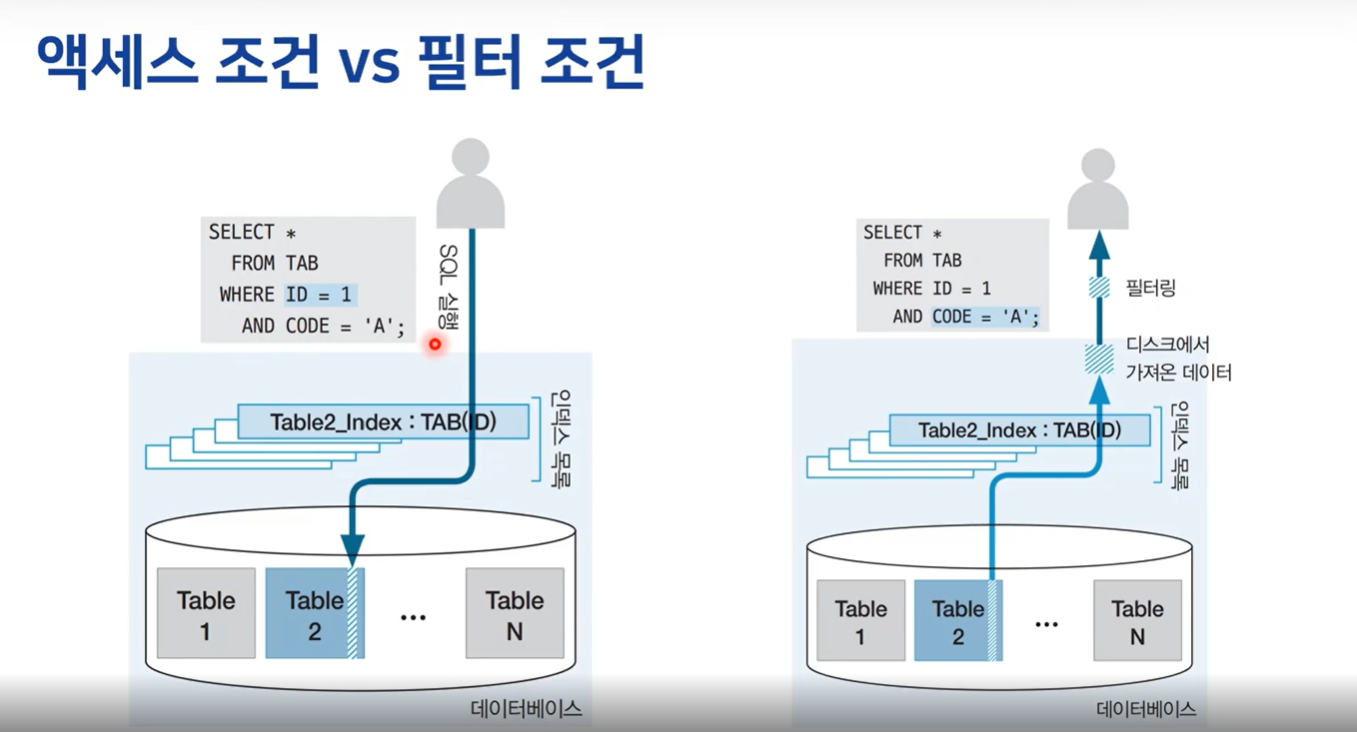
액세스 조건 (Access Condition)
애초에 디스크에 접근해서 데이터를 가지고 올 수 있는 최초의 데이터에 접근해서 범위를 줄일 수 있는 이 조건을 엑세스 조건
필터 조건 (Filter Condition)
가져온 데이터에서 진짜로 사용자한테 리턴하기 직전에 중복을 제거한다거나 정렬을 한다거나 등에 추출하거나 가공이 필요한 이런 조건들을 필터 조건
BlockingQueue - 블로킹 큐
- 기본적으로 스레드 풀은 작업이 제출되면 corePoolSize 의 새 스레드를 추가해서 작업을 할당하고 큐에 작업을 바로 추가하지 않는다
- corePoolSize 를 초과해서 스레드가 실행 중이면 새 스레드를 추가해서 작업을 할당하는 대신 큐에 작업을 추가한다(큐가 가득찰 때까지)
- 큐에 공간이 가득차게 되고 스레드가 maxPoolSize 이상 실행 중이면 더 이상 작업은 추가되지 않고 거부 된다
SynchronousQueue
- newCachedThreadPool() 에서 사용한다
- 내부적으로 크기가 0 인 큐로서 스레드 간에 작업을 직접 전달하는 역할을 하며 작업을 대기열에 넣으려고 할 때 실행할 스레드가 즉시 없으면 새로운 스레드가 생성된다
- 요소를 추가하려고 하면 다른 스레드가 해당 요소를 꺼낼 때까지 현재 스레드는 블로킹되고 요소를 꺼내려고 하면 다른 스레드가 요소를 추가할 때까지 현재 스레드는 블로킹된다
- SynchronousQueue 는 평균적인 처리보다 더 빨리 작업이 요청되면 스레드가 무한정 증가할 수 있다.
LinkedBlockingQueue
- Executors.newFixedThreadPool() 에서 사용한다
- 무제한 크기의 큐로서 corePoolSize 의 스레드가 모두 사용 중인 경우 새로운 작업이 제출 되면 대기열에 등록하고 대기하게 된다
- 무제한 크기의 큐이기 때문에 corePoolSize 의 스레드만 생성하고 더 이상 추가 스레드를 생성하지 않기 때문에 maximumPoolSize 를 설정해도 아무런 효과가 없다
- LinkedBlockingQueue 방식은 일시적인 요청의 폭증을 완화하는 데 유용할 수 있지만 평균적인 처리보다 더 빨리 작업이 도착할 경우 대기열이 무한정 증가할 수 있다
ArrayBlockingQueue
- 내부적으로 고정된 크기의 배열을 사용하여 작업을 추가하고 큐를 생성할 때 최대 크기를 지정해야 하며 한 번 지정된 큐의 크기는 변경할 수 없다
- 큰 대기열과 작은 풀을 사용하면 CPU 사용량 OS 리소스 및 컨텍스트 전환 오버헤드가 최소화 되지만 낮은 처리량을 유발할 수 있다
- 작은 대기열과 큰 풀을 사용하면 CPU 사용률이 높아지지만 대기열이 가득 찰 경우 추가적인 작업을 거부하기 때문에 처리량이 감소할 수 있다
이메일 발송에 Executors.newFixedThreadPool, Executors.newCachedThreadPool, 또는 Executors.newScheduledThreadPool 중 어떤 것을 선택할지는 상황과 요구사항에 따라 다릅니다.
- newFixedThreadPool:
- 쓰레드 풀의 크기를 고정합니다.
- 메일 발송이 많이 발생하고, 발송 작업에 대한 쓰레드 풀의 크기를 제한하고 싶을 때 사용할 수 있습니다.
- 쓰레드의 생성 비용이 크지 않고 고정된 수의 쓰레드가 항상 활성화되어 있어야 할 때 적합합니다.
- newCachedThreadPool:
- 쓰레드 풀의 크기를 동적으로 조정합니다.
- 메일 발송이 가변적이거나 순간적으로 많은 발송이 예상될 때 유용합니다.
- 발송이 적은 경우에는 쓰레드 풀이 작은 크기로 유지됩니다.
- newScheduledThreadPool:
- 스케줄된 작업을 위한 쓰레드 풀을 생성합니다.
- 특정 시간에 메일 발송이 필요하거나 주기적인 작업이 필요한 경우 사용할 수 있습니다.
- **
ScheduledExecutorService**를 이용하여 작업을 일정 시간마다 또는 특정 시간에 실행할 수 있습니다.
추천:
일반적으로 이메일 발송은 비교적 무거운 I/O 작업이므로 **newCachedThreadPool**이나 newFixedThreadPool 중 하나를 선택하는 것이 좋습니다. 둘 다 적절한 사용 사례가 있으며, 발송되는 이메일의 양과 특성에 따라 선택할 수 있습니다.
만약 이메일 발송뿐만 아니라 예약된 작업이나 주기적인 작업도 필요하다면 **newScheduledThreadPool**을 고려할 수 있습니다.
Copyright 201- syh8088. 무단 전재 및 재배포 금지. 출처 표기 시 인용 가능.

